
The Ultimate YCSB Benchmark Guide
The Yahoo! Cloud Serving Benchmarking (YCSB) is the most well-known NoSQL benchmark suite.
This guide provides you with all relevant and up-to-date information about the YCSB. We have also included exclusive interviews from 3 YCSB open-source contributors in the article.
The bonus chapters at the end also explain how databases and workloads can be integrated with the YCSB.
Let's go!
What Is the Yahoo! Cloud Serving Benchmark?
The YCSB is a database benchmark suite. It allows measuring the performance of numerous modern NoSQL and SQL database management systems with simple database operations on synthetically generated data. Here, the YCSB also lends itself to performance comparison of multi-node database systems on distributed infrastructures such as the public cloud.
The YCSB thus provides an important building block in the analysis and evaluation of modern cloud-based database management systems.
The YCSB can be used to compare many, architecturally different databases and measure the performance of different database configurations under different workloads.
A database benchmark suite, such as the YCSB, provides a framework that automates essential tasks in a benchmarking process such as:
- The definition of a workload with the essential parameters.
- The connectivity to the database via the database drivers
- The execution of the workload on the database
- The collection and storage of performance data
Here, these tasks are only part of a complete cloud database benchmarking process, as shown in the graphic below.

The History of the YCSB
As the name suggests, the Yahoo! Cloud Serving Benchmark was developed in 2010 at the then Internet giant Yahoo! The aim was to create a standardized benchmark with which the internal Yahoo database "PNUTS" and other NoSQL databases could be evaluated. In particular, the KPIs "performance" and "scalability" were to be measured and compared.
The Yahoo! cloud serving benchmark client was made freely available as an open-source version at the beginning.
The associated research paper was also published in 2010 and has since been cited over 3,500 times!

Since 2015, you can download, fork and customize the current YCSB version via GitHub. More than 160 developers have since contributed to expand the code base, integrate new databases and keep it up-to-date. The YCSB is licensed for free use under the Apache Licence 2.0.
Meanwhile, the YCSB supports more than 40 NoSQL databases as well as all JDBC-enabled SQL and NewSQL databases.
The YCSB is used for many benchmarking-based database comparisons in both academia and industry.
Its modular architecture has also led to numerous extensions, such as.
- YCSB++ with data consistency assessment and with transactional, more complex request types.
- YCSB-T with transactional performance measures.
- geoYCSB with geo-workload data.
YCSB was the first benchmark suite benchANT integrated in their cloud database benchmarking platform in 2021 for convenient, automated benchmarking measurements. The performance comparison AWS EC2 vs Open Telekom Cloud vs Ionos and the Cassandra 4.0 performance analysis as well as other performance analyses were measured with the YCSB.
Why Is the YCSB Important?
The YCSB became the de-facto database benchmark with the rise of NoSQL databases. This is reflected not only by the countless benchmarking publications with the YCSB, but also by the following GitHub KPIs.
- 3,810 star ratings
- 1,900 forks
- 160 Contributors

Interview Question 1: Why is the YCSB important from your perspective?
filipecosta90 (Performance Engineer @ Redis): > To give a bit of context I'm a Performance Engineer at Redis, meaning I'm deeply interested in any "standard" benchmark that will allow unbiased benchmarks of our DB solutions and also the ones from the competitors. YCSB pioneered on the cloud workload benchmarks (even though I believe there's a large effort that needs to be made to keep YCSB up-to-date given it's a bit stalled and needs a revamp).
lukaszstolarczuk (Software Engineer @ Intel): > Implementing support for new engines and DB's is easy and allows comparing results between many databases. There are many workloads that are common in the IT industry. Thanks to YCSB, we could easily check if our performance is any good.
sachin-sinha (BangDB Author): > The ongoing rapid data trend has been creating opportunities for vendors to innovate and come up with different data platform especially in the converged NoSQL area which has other elements like AI, streaming etc. along with unstructured data store and query support. It is important for such platforms/tools to benchmark with other existing platforms for various reasons such as to know where they stand in terms of performance and scale, and so on. An industry standard benchmark framework therefore is desired especially which is accepted by the users. At the moment, YCSB is such an option and is rather largely accepted by users especially since most of the known and leading platforms are already using it for benchmarking.
peterzheng98 (PhD student): > So YCSB represents a series of scenarios that can be abstracted from the real world like write-intensive or read-intensive. For these scenarios, researchers can get multi-dimensional performance for certain database and apply the best fit one to the real world.
Interview Question 2: Why do you contribute to the further development of the YCSB?
filipecosta90 (Performance Engineer @ Redis): > Mainly to keep it up to date either via improved a specific implementation of the SPEC or by making sure the use-cases it allows to benchmark are still valid/targeting the right questions/use-cases of today's cloud DB era.
lukaszstolarczuk (Software Engineer @ Intel): > We're implementing a new Key-Value storage engine which supports persistent memory devices - pmemkv. Support in YCSB should ease the process of comparing existing solutions with the new ones. Not only for us (developers) but also for our customers when they're using NVDIMMs (persistent memory).
sachin-sinha (BangDB Author): > Like the market is evolving due to the data trend, the YCSB framework should also evolve to capture more aspects and scenarios for benchmarking. Hence YCSB has to be a living project which keeps evolving for better, credible and wider benchmark support. Hence people need to participate in development process for better evolution of the the framework. I participate for the same reason and try to add my bit. Community driven approach adds to the credibility and acceptance element.
peterzheng98 (PhD student): > Since the world is changing fast, maybe something go deprecated. For example, fushsiaOS use all ipv6 for local networking. This means current YCSB test cannot be deployed to it. Therefore, contribution may help following.
Summary
In general, the following reasons are key to its success:
- first NoSQL database benchmark.
- easy extensibility of databases and workloads on code level.
- focus on standard database operations supported by almost any database technology.
- freely accessible transparent open-source benchmark.
- active open-source community
- the need for performance figures for new database technologies
Without the YCSB, most database performance comparisons in academia and even industry would not exist. Many database technologies would not be at the technical level they are now. And many IT companies would be using the wrong database for their software products.
The YCSB enables a deep data-driven decision between many databases, as well as a standardized optimization of different database configurations regarding performance and scalability. In addition, the YCSB is also used to benchmark file systems such as SeaweedFS, REST APIs and data lakes and special storage engines.
Which Databases Does the YCSB Support?
No publicly known database benchmark supports as many databases as the YCSB. At first glance, the databases can be easily identified from the folder structure of the YCSB code, since as a rule each folder belongs to a DBMS.
However, this is only half the truth, as often enterprise versions and different DbaaS versions of a database are also "benchmarkable".
The exact information can be found in the pom.xml files of the folders or the main directory.
Via the driver dependencies contained therein, the possible databases and their versions can be identified.
The following is a complete list of available databases (as of 2021-09-30):
SQL
- MariaDB
- Microsoft SQL Server
- MySQL
- PostgreSQL
- Oracle RDBMS (Multi-Model)
- and actually all databases that support the JDBC driver (version 2.1.1). However, it is often necessary to integrate the special driver separately.
NoSQL
- Aerospike: Key/Value
- Alibaba TableStore: Column Family
- Apache Accumulo: Column Family
- Apache Cassandra: Column Family
- Apache Geode: Key/Value
- Apache HBase: Column Family
- Apache Ignite: Key/Value
- Apache Solr: Document
- Apache Zookeeper: Key/Value
- ArangoDB: Document, (Graph)*
- AWS DynamoDB: Document
- Azure CosmosDB: Document, Column Family, (Graph)*
- Azure Tablestorage: Document
- Couchbase: Document
- Elasticsearch: Document
- Gemfire: Key/Value
- Google BigTable: Column Family
- Google Cloud Datastore: Document
- GridDB: Key/Value
- Hypertable: Colum Family
- Infinispan: Key/Value
- MapR: Column Family
- Memcached: Key/Value
- MongoDB: Document
- Oracle Autonmous Database: Document
- Oracle NoSQL: Key/Value
- OrientDB: Document, Object-Oriented, (Graph)*
- Redis: Key/Value
- Riak KV: Key/Value
- RocksDB: Key/Value
- ScyllaDB: Column Family
- Tarantool: Key/Value
- Voldemort: Key/Value
*For multimodel databases, only Key/Value-like data models are supported. Graph models are not "benchmarkable" with the YCSB.
NewSQL
- Apache Kudu: Key/Value & Relational
- FoundationDB: Key/Value & Relational
- Google Cloud Spanner: Key/Value & Relational
- Many other NewSQL databases support the JDBC driver just like classic SQL databases, and can therefore be integrated just as easily as SQL databases.
Note: Some integrated database drivers of the YCSB do not match the latest available database vendor drivers. Currently, no scientific research exists on the impact of outdated database drivers on benchmarking and the resulting performance figures.
Interview Question 3: Which Databases Have You Already Benchmarkedwith the YCSB?
filipecosta90 (Performance Engineer @ Redis): > Redis (in several flavors), MongoDB, and ElasticSearch.
lukaszstolarczuk (Software Engineer @ Intel): > We've benchmarked few databases to compare: Redis, Memcached, RocksDB, MongoDB (+ our storage engine PMSE based on reverse-engineered WiredTiger API).These benchmarks helped us with Ethernet and/or Kernel tuning and to find out where the bottlenecks are.
sachin-sinha (BangDB Author): > I benchmarked BangDB, Redis, Mongodb, Couchbase and Yugabyte using the YCSB.
peterzheng98 (PhD student): > Memcached. The in memory kv-store shows much not only the database but also the operating system performance.
Which Workloads Does the YCSB Support?

The YCSB workloads can be configured in a much more flexible way in many dimensions, so that almost any "simple" workload can be defined.
- executiontime: Runtime of the workload (in minutes)
- threadcount: Number of parallel threads
- recordcount: Number of initial records
- insertstart: start record (default = 0)
- operationcount: number of operations (default = 1000)
- fieldcount: number of database fields of an entry (default = 10)
- fieldlength: length of each database field (default = 500)
- readallfields: true = all fields are read (default); false = only one field is read (key)
- readproportion: read portion of the workload (0 - 1)
- writeproportion: write portion of the workload (0 - 1)
- updateproportion: Update portion of the workload (0 - 1)
- scanproportion: Scan portion of the workload (0 - 1)
- requestdistribution: request access pattern (UNIFORM, ZIPFIAN, LATEST)
- readmodifywriteproportion: read-modify-write portion of the workload
- insertorder: insert sort order (default = HASHED; ORDERED
- maxscanlength: maximum records of a scan (default = 1000)
- scanlengthdistribution: Distribution of scan length distribution (UNIFORM, ZIPFIAN, LATEST)
These properties are the most important workload dimensions. A complete list can be found on the GitHub wiki. In addition, there are database-specific properties, such as consistency level. However, these must be stored in the DB bindings of the respective database, since these are usually not generalizable. The access distributions describe here, which data records of which database table position are read how often.
Note 1: The configuration of the parameters is error-prone because there are no control checks. Many mutual influences are not obvious and can lead to erroneous benchmark measurements. Therefore, a certain amount of caution and logical checking is advisable when configuring your own workloads. In addition, it is often useful to benchmark new workloads only briefly on a test basis before performing longer benchmark runs.
Note 2: The access distribution "LATEST" indicates accesses to the last records of the database. However, this refers only to the last records of the initial records, not the last records written to the database during the benchmark. This behavior does not match the natural behavior of many IoT & e-commerce applications, for example.
In the benchANT benchmarking platform, similar workloads are implemented after. Furthermore, all configuration options are so available via the benchmarking backend API. Feel free to (contact)[/contact] us for specific workloads.
What Results Does the YCSB Deliver?
The YCSB has been developed and designed to measure performance and scalability metrics. As a result, it provides txt files with time series measurement data as well as aggregated values of these measurement series at the end of the file.

Every 10 seconds (configurable) it returns the sum of all operations performed and the number of operations of the last 10 seconds. These are additionally separated individually for the individual database operation classes READ, INSERT, ... and output in each case with statistical values.
At the end of the measurement, the most important performance KPIs are output:
- Runtime
- Throughput [ops/sec]
- Latency (avg)
- Latency (min)
- Latency (max)
- Latency (95th percentile)
- Latency (99th percentile)
These aggregated performance KPIs are a good start for performance analysis of the measured setup A graphical presentation of the results must be done independently and is necessary for a better understanding of the results and, if necessary, for data cleaning.
Also these last two points - data cleansing and graphical preparation - have been seamlessly integrated by benchANT into its benchmarking platform, so that no additional manual work is required and the performance KPIs can be evaluated directly.
How Do I Run a YCSB MongoDB Benchmark?
The procedure for performing a benchmark with the YCSB is similar for all databases. As an example, a concrete YCSB benchmark for MongoDB in the AWS Cloud will be described in order to address database-specific subtleties in distributed cloud systems.
The following sections describe the procedure on a technical level to implement the required steps from Figure X. Since benchmarking is a continuous process in which different configurations of cloud resources, DBMS configurations and benchmark configurations are examined iteratively, a special focus is placed on automation here.
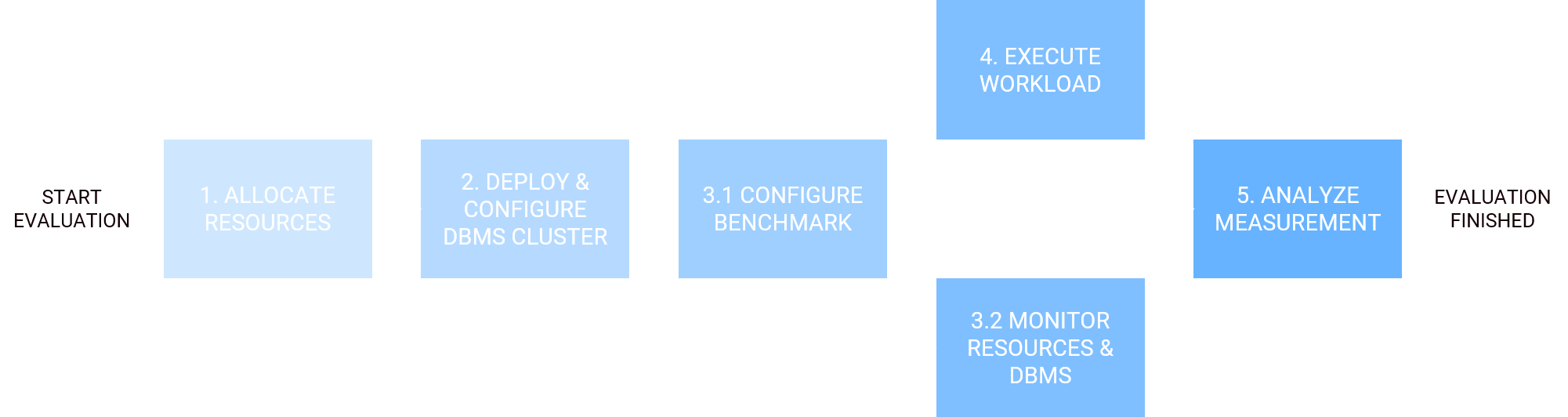
1. Allocate AWS Cloud Resources.
First, you can of course create the necessary VM resources to install MongoDB using the EC2 Web Console or the EC2 API. However, this is time-consuming, especially if you want to benchmark many VM flavors.
Therefore, it is a good idea to use automation tools like Ansible, Chef or Terraform. These allow the declarative specification of a deployment model to generate the desired resources and abstract the direct interaction with the EC2 API. The deployment model can thus be easily extended and reused for additional VM flavors.
2. Install and Configure MongoDB Database
The installation of MongoDB on the created VMs can be done manually via the CLI or you can also use the selected automation tool. Often there are also ready-made models for the installation of MongoDB, for example the MongoDB Playbook for Ansible.
3. Install Benchmark
To install the YCSB, a separate VM is also required. It should be ensured that this VM has enough cores to be able to map the desired workload intensity (i.e. numberOfThreads) and does not become a bottleneck.
It is also a good idea to constantly monitor the resource utilization of the benchmarking VM, either with an OS tool like top/htop or a comprehensive monitoring framework like Telegraf + InfluxDB.
Java 8 must now be installed on this VM, and the desired version of the YCSB release must be downloaded.
4. Configure and Run the Workload
To configure the desired workload, you can either access the predefined Templates and extend them, or you can define your own complete workload via the Command Line.
It is important to know here that the YCSB supports two phases: Load and Run.
In the Load phase the initial data records are written into the database, i.e. it is a 100% insert workload. In the Run phase the defined mix of CRUD operations is executed.
Below we show the Load and Run commands to start an IoT-driven workload where 2,000,000 records are written to the database in the Load phase and then an 80% Insert / 20% Read workload mix is executed in the Run phase.
Load Phase Command-Line (YCSB Client 0.17.0):
-db site.ycsb.db.MongoDbClient -s -p mongodb.url=mongodb://<ip:port>/ycsb?w=1&j=false -p workload=site.ycsb.workloads. CoreWorkload -p maxexecutiontime=1800 -threads 64 -p recordcount=2000000 -p operationcount=10000000 -p fieldcount=10 -p fieldlength=500 -p requestdistribution=zipfian -p insertorder=ordered -p readproportion=0. 2 -p updateproportion=0.0 -p insertproportion=0.8 -p scanproportion=0.0 -p maxscanlength=1000 -p scanlengthdistribution=uniform -p core_workload_insertion_retry_limit=3 -p core_workload_insertion_retry_interval=3 -load
Run-Phase Command-Line (YCSB Client 0.17.0):
-db site.ycsb.db.MongoDbClient -s -p mongodb.url=mongodb://<ip:port>/ycsb?w=1&j=false -p workload=site.ycsb.workloads. CoreWorkload -p maxexecutiontime=1800 -threads 64 -p recordcount=2000000 -p operationcount=10000000 -p fieldcount=10 -p fieldlength=500 -p requestdistribution=zipfian -p insertorder=ordered -p readproportion=0. 2 -p updateproportion=0.0 -p insertproportion=0.8 -p scanproportion=0.0 -p maxscanlength=1000 -p scanlengthdistribution=uniform -p core_workload_insertion_retry_limit=3 -p core_workload_insertion_retry_interval=3 -p insertstart=2000001 -t
After successfully running the workload, the cloud resources used should be released again to avoid incurring unnecessary costs. For further benchmark runs, the process should be used on new resources from the beginning to avoid caching and other artifacts that can affect the measurement result.
5. Analyse and Visualize Data
Since the YCSB itself only provides the results as text, CSV or JSON, further steps are required to merge and visualize the data from several measurement series. For this purpose, it is useful to implement appropriate scripts in R or Python, which parse the YCSB results and convert them into a suitable data format for analysis or visualization, for example Dataframes in Python. In addition, there are a number of tools that enable a standardized visualization of the results from the data frames, for example Seaborn, Bokeh or Plotly.
All the necessary benchmarking process steps, from allocating the cloud resources to the visual preparation of the measurement results, are integrated and automated in the Benchmarking Platform from benchANT. This means that a benchmarking process is now also possible for significantly less specialized IT experts.
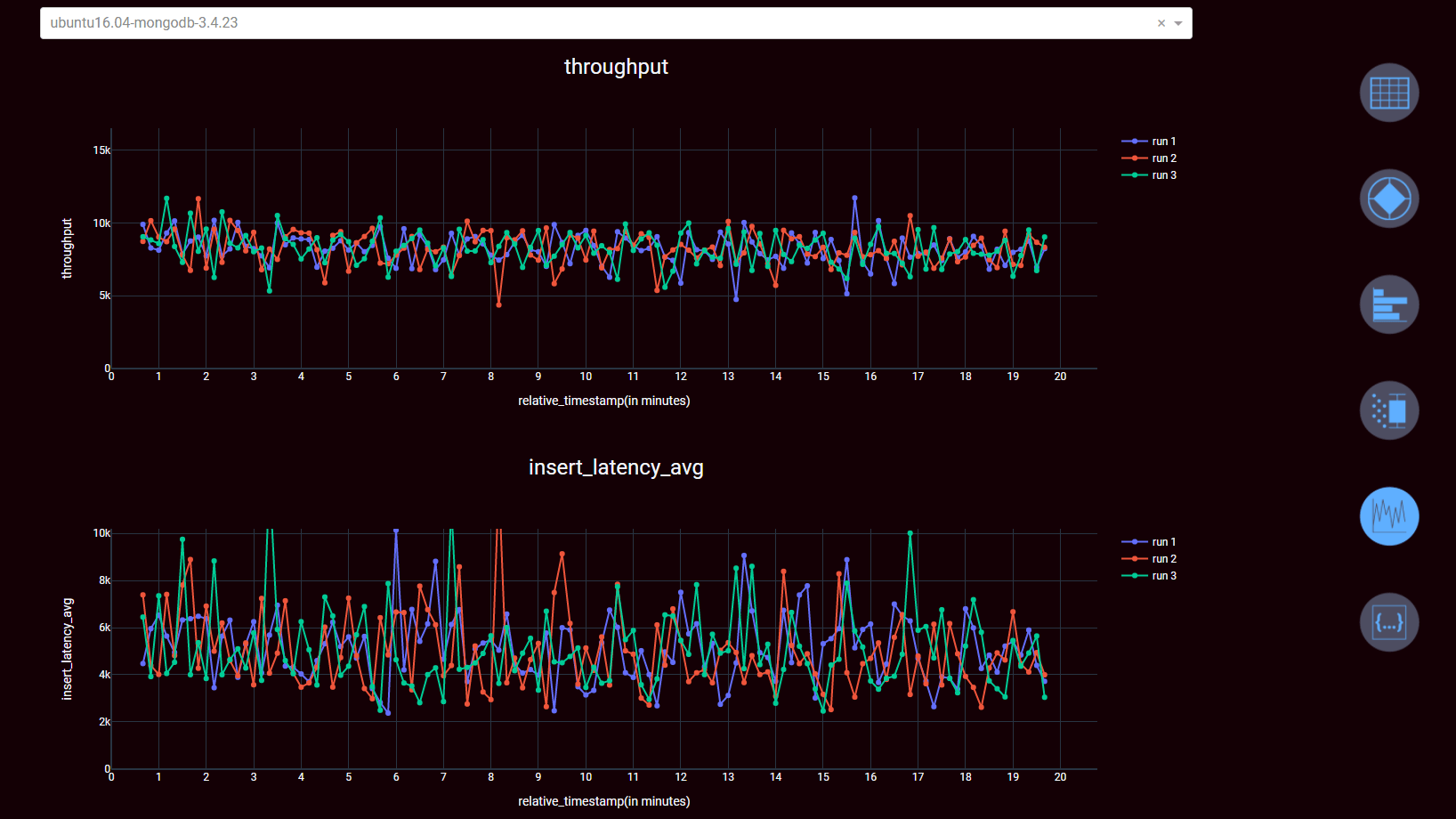
Conclusion
The YCSB is a functional and important NoSQL database benchmark. It enables important performance analyses and performance comparisons.
It can be used for manual distributed database benchmarks. It is also available for automated cloud database benchmarks in the benchANT platform.
Which benchmarks do you use?
And which databases would you like to benchmark?
Bonus #1: How Do I Integrate a New Database into the YCSB?
The YCSB already has a large number of DBMS integrations as shown above. This is especially due to the simple integration process of new databases into the YCSB.
Any database that can perform the following 5 basic operations can be integrated into the YCSB:
- Read a single record
- Perform a range scan
- Update a single record
- Insert a single record
- Delete a single record
This applies to almost all known databases.

The process of integrating a new database into the YCSB is relatively simple:
- forking of the GitHub YCSB repository
- creation of an own project folder
- extend the
com.yahoo.ycsb.DBclass with an own constructor - optional: create init() method for the DB
- implement the 5 database methods
- compile the database interface layer
- test the database layer
- execute YCSB client
- optionally: make a pull request for GitHub
- optionally: Maintaining the GitHub project folder
Detailed instructions of the integration process can be found in the Wiki of the YCSB GitHub repository as well as here.
If you have any questions about implementing a database in the YCSB, please feel free to contact us. We will be happy to help you with this, or can take over this task.
Bonus #2: How Do I Integrate a New Workload into the YCSB?
While numerous new databases have been added to the YCSB in recent years, not a single new workload has been added since the release of the YCSB.
This is in no way because adding a new workload is complicated or time-consuming. On the contrary, it is relatively simple. The reason for this is that adding a new workload to the GitHub repository also entails a responsibility to integrate and maintain all DB bindings with that workload. Of course, no one wants to go to this trouble voluntarily.
Therefore, the integration of new workloads is only done on (private) forks of the YCSB and only for the databases that are relevant for the individual benchmark. This is why one finds many benchmark results with deviating workloads.
Creating a new YCSB workload is a simple process once you understand the structure and the workload configuration parameters.
In order to define a YCSB workload, the data sets on the one hand and the transaction sets on the other hand have to be specified. These workload specifications can be integrated into the YCSB either via a new parameter file or via a new Java class.
A detailed implementation guide is available on the YCSB-GitHub-Wiki.
With benchANT, individual workloads can be configured and executed using a clear GUI.