
NoSQL Benchmark: MongoDB vs ScyllaDB (Part II)
In our previous study to MongoDB and ScyllaDB we analyzed the technical characteristics of these two important NoSQL databases.
Now, we added more than 133 performance measurement results in an in-depth benchmarking study for performance and scalability.
Let's dive into the extensive results!
Table of Contents
- Chapter 1: Executive Summary
- Chapter 2: Introduction
- Chapter 3: Benchmarking Setup
- Chapter 4: Performance Results - Social Workload
- Chapter 5: Performance Results - Caching Workload
- Chapter 6: Performance Results - Sensor Workload
- Chapter 7: Conclusion
- Appendix
- About the Author: Dr. Daniel Seybold
Executive Summary
NoSQL databases promise to provide high performance and horizontal scalability for data intensive workloads. In this report, we benchmark the performance and scalability of the market leading general purpose NoSQL database MongoDB and its performance-oriented challenger ScyllaDB.
- The benchmarking study is carried out against the DBaaS offers of each database vendor to ensure a fair comparison.
- The DBaaS clusters range from 3 to 18 nodes, classified in three scaling sizes that are comparably priced.
- The benchmarking study comprises three workload types that cover read-heavy, read-update and write-heavy application domains with data set sizes from 250GB to 10TB.
- The benchmarking study compares a total of 133 performance measurements that range from throughput (per cost) to latencies to scalability.
Results
ScyllaDB outperforms MongoDB in 132 of 133 measurements.
- For all the applied workloads, ScyllaDB provides higher throughput (up to 20 times) results compared to MongoDB.
- Regarding the latency results, ScyllaDB achieves P99 latencies below 10 ms for insert, read and write operations for almost all scenarios. In contrast, MongoDB achieves P99 latencies below 10 ms only for certain read operations, while the MongoDB insert and update latencies are up to 68 times higher compared to ScyllaDB.
- The scalability results demonstrate that ScyllaDB achieves up to near linear scalability, while MongoDB shows less efficient horizontal scalability.
- The price-performance ratio clearly shows the strong advantage of ScyllaDB with up to 19 times better price-performance ratios, depending on the workload and data set size.
In summary, this benchmarking study shows that ScyllaDB provides a great solution for applications that operate on data sets in the terabyte range and that require high (e.g, over 50,000 operations per second) throughput while providing predictable low latency for read and write operations. It also needs to be considered that this study does not target advanced data models such as time series or complex operation types such as aggregates or scans, which are subject to future benchmark studies.
Introduction
The NoSQL database landscape is continuously evolving. Over the last 15 years, it has already introduced many options and tradeoffs when it comes to selecting a high performance and scalable NoSQL database. In this report, we address the challenge of selecting a high performance database by evaluating two popular NoSQL databases: MongoDB, the market leading general purpose NoSQL database and ScyllaDB, the high-performance NoSQL database for large scale data. See our technical comparison article for an in depth analysis of MongoDB’s and ScyllaDB’s data model, query languages and distributed architecture. In addition, ScyllaDB itself has its own page comparing MongoDB and ScyllaDB.
For this project, we benchmarked both database technologies to get a detailed picture of their performance, price-performance and scalability capabilities under different workloads. For creating the workloads, we use the Yahoo! Cloud Serving Benchmark (YCSB), an open source and industry standard benchmarking tool. Database benchmarking is often said to be non-transparent and to compare apples with pears. In order to address these challenges, this benchmark comparison is based on benchANT’s scientifically proven Benchmarking-as-a-Service platform. The platform ensures a reproducible benchmark process (for more details, see the associated research papers on Mowgli and benchANT) which follows established guidelines for database benchmarking.
This benchmarking project was carried out by benchANT and was sponsored by ScyllaDB with the goal to provide a fair, transparent and reproducible comparison of both database technologies. For this purpose, all benchmarks were carried out on the database vendors’ DBaaS offers, namely MongoDB Atlas and ScyllaDB Cloud, to ensure a comparable production ready database deployment. Further, the applied benchmarking tool was the standard Yahoo! Cloud Serving benchmark and all applied configuration options are exposed. In addition, all results are publicly available on GitHub. In consequence, the interested reader is able to reproduce the results on their own even without the benchANT platform.
Benchmark Setup
DBaaS Setup
Starting from our technical comparison, MongoDB and ScyllaDB follow different distributed architecture approaches. Consequently, a fair comparison can only be achieved by selecting comparable cluster sizes in terms of costs/month or total compute power. Our comparison selects comparably priced cluster sizes with comparable instance types, having the goal to compare the provided performance (throughput and latency) as well as scalability for three cluster sizes under growing workloads.
The following table describes the selected database cluster sizes to be compared and classified into the scaling sizes small, medium and large. All benchmarks are run on AWS in the us-west region and the prices are based on the us-west-1 (N. California) region, which means that the DBaaS instances and the VMs running the benchmark instances are deployed in the same region. VPC peering is not activated for MongoDB or ScyllaDB. For MongoDB all benchmarks were run again version 6.0, for ScyllaDB against 2022.2. The period in which the benchmarks were carried out was March to June 2023.
| DBaaS | Cluster Type | Version | Instance Type | Instance Specs | Total Data Nodes | Storage Capacity | Monthly Costs |
|---|---|---|---|---|---|---|---|
| MongoDB Atlas (small) | replica set | 6 | M60_NVME | 8 vCPU /61 GB RAM | 3 | 1.6 TB | $3,880 |
| ScyllaDB Cloud (small) | n/a | 2022.2.0 | i4i.2xlarge | 8 vCPU /64 GB RAM | 3 | 1.3 TB | $4,620 |
| MongoDB Atlas (med.) | sharded | 6 | M80_NVME | 16 vCPU /122 GB RAM | 9 | 4.8 TB | $19,180 |
| ScyllaDB Cloud (med.) | n/a | 2022.2.0 | i4i.4xlarge | 16 vCPU /128 GB RAM | 6 | 5.2 TB | $17,870 |
| MongoDB Atlas (large) | sharded | 6 | M200_NVME | 32 vCPU /244 GB RAM | 18 | 18.6 TB | $69,120 |
| ScyllaDB Cloud (large) | n/a | 2022.2.0 | i4i.8xlarge | 32 vCPU /256 GB RAM | 12 | 20.9 TB | $73,932 |
Workload Setup
In order to simulate realistic workloads, we use YCSB in the latest available version 0.18.0-SNAPSHOT from the original GitHub repository. Based on YCSB, we define three workloads that map to real world use cases. The key parameters of each workload are shown in the following table, and the full set of applied parameters is available in the GitHub repository.
| Workload | Distribution | Reads [%] | Updates [%] | Inserts [%] | Data Size small/med- ium/large [TB] | Record Size [KB] |
|---|---|---|---|---|---|---|
| caching (YCSB A) | uniform & hotspot | 50 | 50 | 0 | 0.5/1/10 | 1 |
| social (YCSB B) | uniform & hotspot | 95 | 5 | 0 | 0.5/1 | 1 |
| sensor | latest | 10 | 0 | 90 | 0.25/0.5 | 1 |
The caching and social workloads are executed with two different request patterns: The uniform request distribution simulates a close-to-zero cache hit ratio workload, and the hotspot distribution simulates an almost 100% cache hit workload.
All benchmarks are defined to run with a comparable client consistency. For MongoDB, the client consistency writeConcern=majority and readPreference=primary is applied. For ScyllaDB, writeConsistency=QUORUM and readConsistency=QUORUM are used. For more details on the client consistencies, read some of the technical nuggets below and also, feel free to read our detailed comparison of the two databases. In addition, we have also analyzed the performance impact of weaker consistency settings for the social workload and caching workload.
Benchmark Process
In order to achieve a realistic utilization of the benchmarked database, each workload is scaled with the target database cluster (i.e. small, medium and large). For this, the data set size, the number of YCSB instances and the number of client threads is scaled accordingly to achieve 70-80% load with a stable throughput on the target database cluster.
Each benchmark run is carried out by the benchANT platform that handles the deployment of the required number of EC2 c5.4xlarge VMs with 16 vCores and 32GB RAM to run the YCSB instances, deployment of the DBaaS instances and orchestration of the LOAD and RUN phases of YCSB. After loading the data into the DB, the cluster is given a 15-minute stabilization time before starting the RUN phase executing the actual workload. In addition, we configured one workload to run for 12 hours to ensure the benchmark results are also valid for long-running workloads.
For additional details on the benchmarking methodology (for example, how we identified the optimal throughput per database and scaling size), see “Benchmarking Process” in the Appendix.
Limitations of the Comparison
The goal of this benchmark comparison focuses on performance and scalability in relation to the costs. It is by no means an all-encompassing guide on when to select MongoDB or ScyllaDB. Yet, by combining the insights of the technical comparison with the results of this benchmark article, the reader gets a comprehensive decision base.
YCSB is a great benchmarking tool for relative performance comparisons. However, when it comes to measuring absolute latencies under steady throughput, it is affected by the coordinated omission problem. The latest release of the YCSB introduces an approach to address this problem. Yet, during the benchmark dry runs, it turned out that this feature is not working as expected (unrealistic high latencies were reported).
In the early (and also later) days of cloud computing, the performance of cloud environments was known to be volatile. This required experimenters to repeat experiments several times at different times of the day. Only then were they able to gather statistically meaningful results. Recent studies such as the one by Scheuner and Leitner show that this has changed. AWS provides particularly stable service quality. Due to that, all experiments presented here were executed once.
Benchmarking Results
In the following sections, we present the benchmark results per workload. Each workload results section contains the following subsection:
- Benchmark characteristics provide a brief outline of the applied workload
- Key insights provide a high level summary of the results
- Throughput results compare the throughput per request distribution
- Scalability results present the throughput scaling
- Throughput per cost ratio provides analysis of costs per month in relation to the provided throughput
- Latency results compare the 99th percentile of measured latencies
- Technical nuggets analyze additional configuration options and how they impact the resulting performance. It needs to be highlighted that these measurements are not 1:1 comparable to the standard measurements presented earlier, because a simplified benchmark process (compared to the standard benchmark process) was applied that differs in the following aspects: (i) We do not apply a target throughput, but run the YCSB with unlimited throughput and an identical number of threads for both databases. (ii) a single YCSB instance is applied.
Performance Results - Social Workload
The social workload is based on the YCSB Workload B and creates a read-heavy workload, with 95% read operations and 5% update operations. We use two shapes of this workload, which differ in terms of the request distribution patterns, namely uniform and hotspot distribution. These workloads are executed against the small database scaling size with a data set of 500GB and against the medium scaling size with a data set of 1TB.

Throughput Results
The throughput results for the social workload with the uniform request distribution show that the small ScyllaDB cluster is able to serve 60 kOps/s with a cluster CPU utilization of ~85% while the small MongoDB cluster serves only 10 kOps/s under a comparable cluster utilization of 80-90%. For the medium cluster sizes, ScyllaDB achieves an average throughput of 232 kOps/s showing ~85% cluster utilization while MongoDB achieves 42 kOps/s at a CPU utilization of ~85%.

The throughput results for the social workload with the hotspot request distribution show a similar trend, but with higher throughput numbers since the data is mostly read from the cache. The small ScyllaDB cluster serves 152 kOps/s while the small MongoDB serves 14 kOps/s. For the medium cluster sizes, ScyllaDB achieves an average throughput of 587 kOps/s and MongoDB achieves 48 kOps/s.

Scalability Results
These results also enable us to compare the theoretical throughput scalability with the actually achieved throughput scalability. For this, we consider a simplified scalability model that focuses on compute resources. It assumes the scalability factor is reflected by the increased compute capacity from the small to medium cluster size. For ScyllaDB, this means we double the cluster size from 3 to 6 nodes and also double the instance size from 8 cores to 16 cores per instance, resulting in a theoretical scalability of 400%. For MongoDB, we move from one replica set of three data nodes to a cluster with three shards and nine data nodes and increase the instance size from 8 cores to 16 cores, resulting in a theoretical scalability factor of 600%.
The ScyllaDB scalability results for the uniform and hotspot distributions both show that ScyllaDB is close to achieving linear scalability by achieving a throughput scalability of 386% (of the theoretically possible 400%).


With MongoDB, the gap between theoretical throughput scalability and the actually achieved throughput scalability is significantly higher. For the uniform distribution, MongoDB achieves a scaling factor of 420% (of the theoretically possible 600%). For the hotspot distribution, we measure 342% (of the theoretically possible 600%).


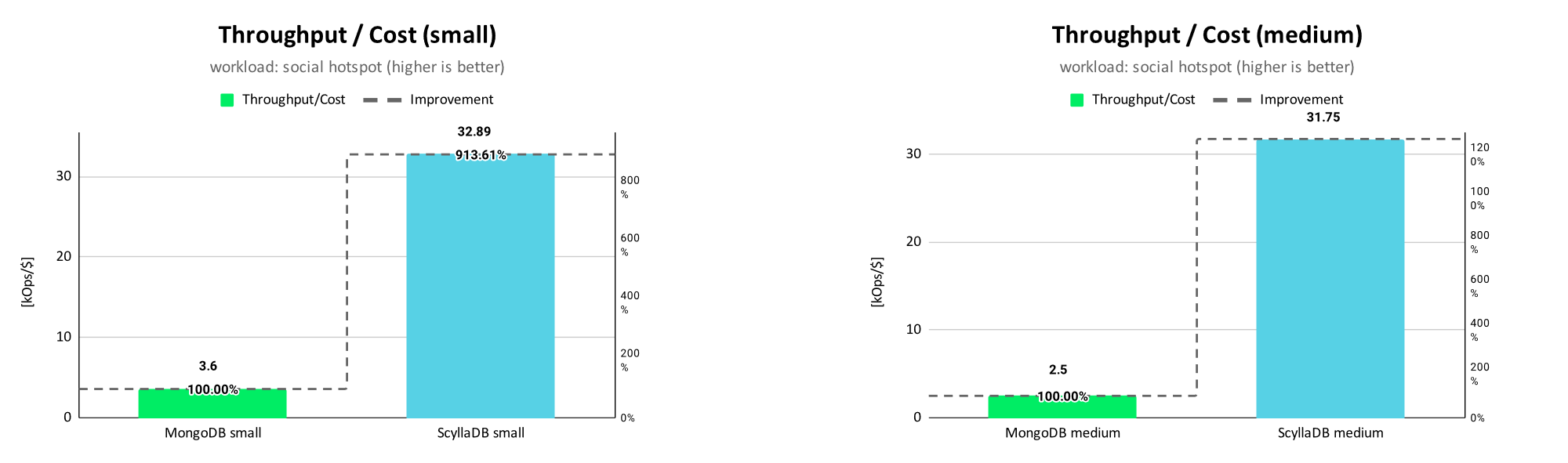
Throughput per Cost Results
In order to compare the costs/month in relation to the provided throughput, we take the MongoDB Atlas throughput/$ as baseline (i.e. 100%) and compare it with the provided ScyllaDB Cloud throughput/$.
The results for the uniform distribution show that ScyllaDB provides five times more operations/$ compared to MongoDB Atlas for the small scaling size and 5.7 times more operations/$ for the medium scaling size.
For the hotspot distribution, the results show an even better throughput/cost ratio for ScyllaDB, providing 9 times more operations/$ for the small scaling size and 12.7 times more for the medium scaling size.

Latency Results
For the uniform distribution, ScyllaDB provides stable and low P99 latencies for the read and update operations for the scaling sizes small and medium. MongoDB generally has higher P99 latencies. Here, the read latencies are 2.8 times higher for the small scaling size and 5.5 times higher for the medium scaling size. The update latencies show an even more distinct difference; MongoDB’s P99 update latency in the small scaling size is 47 times higher compared to ScyllaDB and 12 times higher in the medium scaling size.

For the hotspot distribution, the results show a similar trend for the stable and low ScyllaDB latencies. For MongoDB, read and update latencies increase from the small to medium scaling size. It is interesting that in contrast to the uniform distribution, the read latency only increases by a factor of 2.8 while the update latency increases by 970%.

Technical Nugget 1 - Data Model Performance Impact
The default YCSB data model is composed of a primary key and a data item with 10 fields of strings that results in a document with 10 attributes for MongoDB and a table with 10 columns for ScyllaDB. We analyze how performance changes if a pure key-value data model is applied for both databases: a table with only one column for ScyllaDB and a document with only one field for MongoDB
The results show that for ScyllaDB the throughput improves by 24% while for MongoDB the throughput increase is only 5%.

Technical Nugget 2 - Client Consistency Performance Impact
All standard benchmarks are run with the MongoDB client consistency writeConcern=majority/readPreference=primary and for ScyllaDB with writeConsistney=QUORUM/readConsistency=QUORUM. Besides these client consistent configurations, we also analyze the performance impact of weaker read consistency settings. For this, we enable MongoDB to read from the secondaries (readPreference=secondarypreferred) and set readConsistency=ONE for ScyllaDB.
The results show an expected increase in throughput: for ScyllaDB 56% and for MongoDB 49%.

Performance Results - Caching Workload
The caching workload is based on the YCSB Workload A and creates a read-update workload, with 50% read operations and 50% update operations. The workload is executed in two versions, which differ in terms of the request distribution patterns (namely uniform and hotspot distribution). This workload is executed against the small database scaling size with a data set of 500GB, the medium scaling size with a data set of 1TB and a large scaling size with a data set of 10TB.
In addition to the regular benchmark runtime of 30 minutes, a long-running benchmark over 12 hours is executed.

Throughput Results
The throughput results for the uniform workload with the uniform request distribution show that the small ScyllaDB cluster is able to serve 77 kOps/s with a cluster utilization of ~87% while the small MongoDB serves only 5 kOps/s under a comparable cluster utilization of 80-90%. For the medium cluster sizes, ScyllaDB achieves an average throughput of 306 kOps/s by ~89% cluster utilization and MongoDB 17 kOps/s. For the large cluster size, ScyllaDB achieves 894 kOps/s against 45 kOps/s of MongoDB.
Note that client side errors occurred when inserting the initial 10TB on MongoDB large; as a result, only 5TB of the specified 10TB were inserted. However, this does not affect the results of the caching workload because the applied YCSB version only operates on the key range 1 - 2.147.483.647 (INTEGER_MAX_VALUE); for more details, see Support for Data Sets of >2.1 TB. This fact leads to an advantage for MongoDB, because MongoDB’s cache had only to deal with 2,100,000,000 of accessed records (i.e. 2.1TB) while ScyllaDB’s cache had to deal with the full 10,000,000,000 records (i.e. 10TB).

The caching workload with the hotspot distribution is only executed against the small and medium scaling size. The throughput results for the hotspot request distribution show a similar trend, but with higher throughput numbers since the data is mostly read from the cache. The small ScyllaDB cluster serves 153 kOps/s while the small MongoDB only serves 8 kOps/s. For the medium cluster sizes, ScyllaDB achieves an average throughput of 559 kOps/s and MongoDB achieves 28 kOps/s.

Scalability Results
Analogous to the social workload, the throughput results allow us to compare the theoretical throughput scalability with the actually achieved scalability. For ScyllaDB, the maximum theoretical scaling factor for throughput for the uniform distribution is 1600% when scaling from small to large. For MongoDB, the theoretical maximal throughput scaling factor is 2400% when scaling from small to large.
The ScyllaDB scalability results show that scaling from small to medium is very close to achieving linear scalability by achieving a throughput scalability of 397% of the theoretically possible 400%. Considering the maximal scaling factor from small to large, ScyllaDB achieves 1161% of the theoretical 1600%.
For the hotspot distribution, the small and medium cluster sizes are benchmarked. ScyllaDB achieves a throughput scalability of 365% of the theoretical 400%.


The MongoDB scalability results for the uniform distribution show that MongoDB scaled from small to medium achieves a throughput scalability of 340% of the theoretical 600%. Considering the maximal scaling factor from small to large, MongoDB achieves only 900% of the theoretically possible 2400%.
MongoDB achieves a throughput scalability of 350% of the theoretical 600% for the hotspot distribution.


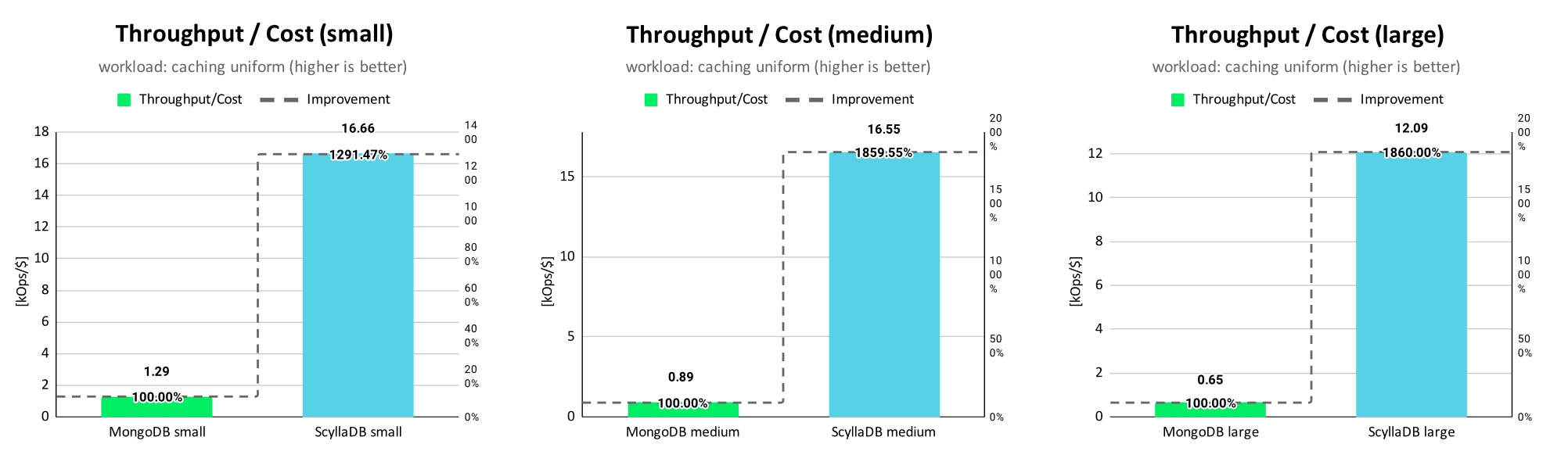
Throughput per Cost Results
In order to compare the costs/month in relation to the provided throughput, we take the MongoDB Atlas throughput/$ as baseline (i.e. 100%) and compare it with the provided ScyllaDB Cloud throughput/$.
The results for the uniform distribution show that ScyllaDB provides 12 times more operations/$ compared to MongoDB Atlas for the small scaling size and 18 times more operations/$ for the scaling sizes medium and large.
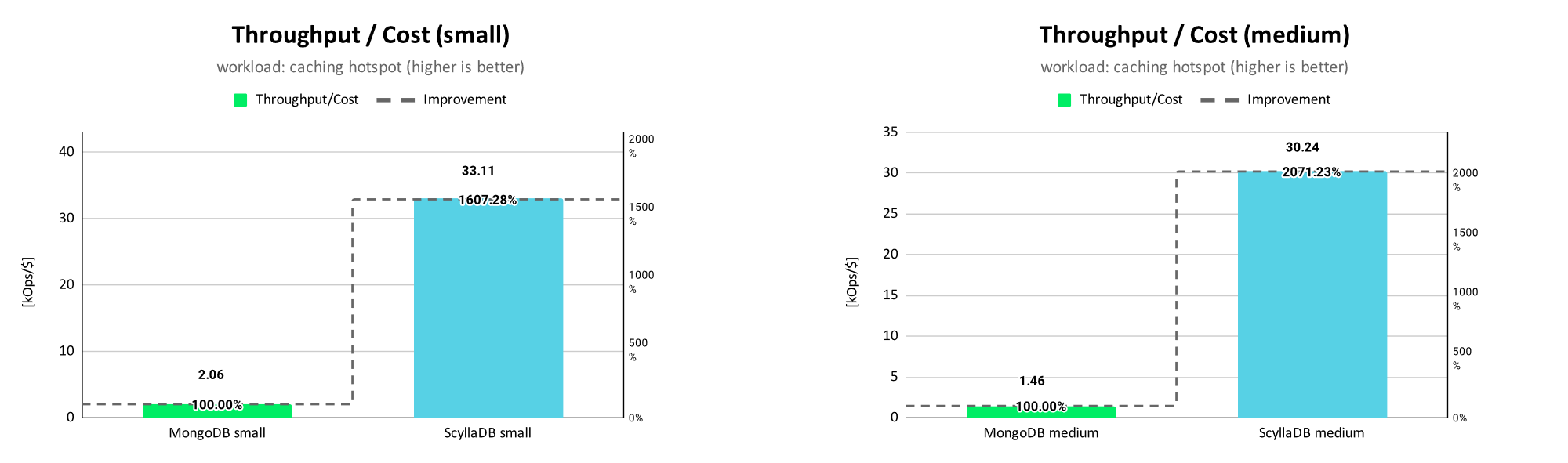
For the hotspot distribution, the results show a similar trend where ScyllaDB provides 16 time more operations/$ for the small scaling size and 20 times for the medium scaling size.
Latency Results
The P99 latency results for the uniform distribution show that ScyllaDB and MongoDB provide stable P99 read latencies. Yet, the values for ScyllaDB are constantly lower compared to the MongoDB latencies. An additional insight is that the ScyllaDB read latency doubles from medium to large (from 8.1 to 16.1 ms). The MongoDB latency decreases by 1 millisecond (from 23.3 to 22.3 ms), but still does not match the ScyllaDB latency.
For the update latencies, the results show a similar trend as for the social workload, where ScyllaDB provides stable and low update latencies while MongoDB provides up to 73 times higher update latencies.
For the hotspot distribution, the results show a similar trend as for the uniform distribution. Both databases provide stable read latencies for the small and medium scaling size, with ScyllaDB providing the lower latencies.
For updates, the ScyllaDB latencies are stable across the scaling sizes and slightly lower than for the uniform distribution. Compared to ScyllaDB, the MongoDB update latencies are 25 times higher for the small scaling size and 44 times higher for the medium scaling size respectively.


Technical Nugget 1 - 12h Run
In addition to the default 30 minute benchmark run, we also select the scaling size large with the uniform distribution for a long-running benchmark of 12 hours.
For MongoDB, we select the determined 8 YCSB instances with 100 threads per YCSB instance and run the caching workload in uniform distribution for 12 hours with a target throughput of 40 kOps/s.
The throughput results show that MongoDB provides the 40 kOps/s constantly over time as expected.

The P99 read latencies over the 12 hours show some peaks in the latencies that reach 20ms and 30ms and an increase of spikes after 4 hours runtime. On average, the P99 read latency for the 12h run is 8.7 ms; for the regular 30 minutes run, it is 5.7 ms.
The P99 update latencies over the 12 hours show a spiky pattern over the entire 12 hours with peak latencies of 400 ms. On average, the P99 update latency for the 12h run is 163.8 ms while for the regular 30 minutes run it is 35.7 ms (see also Latency Results).


For ScyllaDB, we select the determined 16 YCSB instances with 200 threads per YCSB instance and run the caching workload in uniform distribution for 12 hours with a target throughput of 500 kOps/s.
The throughput results show that ScyllaDB provides the 500 kOps/s constantly over time as expected.

The P99 read latencies over the 12 hours stay constantly below 10 ms except for one peak of 12 ms. On average, the P99 read latency for the 12h run is 7.8 ms.
The P99 update latencies over the 12 hours show a stable pattern over the entire 12 hours with an average P99 latency of 3.9 ms.


Technical Nugget 2 - Insert Performance
In addition to the three defined workloads, we also measured the plain insert performance for the small scaling size (500 GB), medium scaling size (1 TB) and large scaling size (10 TB) into MongoDB and ScyllaDB. It needs to be emphasized that batch inserts were enabled for MongoDB but not for ScyllaDB (since YCSB does not support it for ScyllaDB).
The following results show that for the small scaling size, the achieved insert throughput is on a comparable level. However, for the larger data sets of the medium and large scaling sizes, ScyllaDB achieves a 3 times higher insert throughput for the medium size benchmark. For the large-scale benchmark, MongoDB was not able to fully ingest the full 10TB of data due to client side errors, resulting in only 5TB inserted data (for more details, see Throughput Results). Yet, ScyllaDB outperforms MongoDB by a factor of 5.

Technical Nugget 3 - Client Consistency Performance Impact
In addition to the standard benchmark configurations, we also run the caching workload in the uniform distribution with weaker consistency settings. Namely, we enable MongoDB to read from the secondaries (readPreference=secondarypreferred) and for ScyllaDB we set the readConsistency=ONE.
The results show an expected increase in throughput: for ScyllaDB 23% and for MongoDB 14%. This throughput increase is lower compared to the client consistency impact for the social workload since the caching workload is only a 50% read workload and only the read performance benefits from the applied weaker read consistency settings. It is also possible to further increase the overall throughput by applying weaker write consistency settings.

Performance Results - Sensor Workload
The sensor workload is also based on the YCSB and its default data model, but with an operation distribution of 90% insert operations and 10% read operations that simulate a real-world IoT application. The workload is executed with the latest request distribution patterns. This workload is executed against the small database scaling size with a data set of 250GB and against the medium scaling size with a data set of 500GB.

Throughput Results
The throughput results for the sensor workload show that the small ScyllaDB cluster is able to serve 60 kOps/s with a cluster utilization of ~89% while the small MongoDB cluster serves only 8 kOps/s under a comparable cluster utilization of 85-90%. For the medium cluster sizes, ScyllaDB achieves an average throughput of 236 kOps/s with ~88% cluster utilization and MongoDB 21 kOps/s with a cluster utilization of 75%-85%.

Scalability Results
Analogous to the previous workloads, the throughput results allow us to compare the theoretical scale up factor for throughput with the actually achieved scalability. For ScyllaDB the maximal theoretical throughput scaling factor is 400% when scaling from small to medium. For MongoDB, the theoretical maximal throughput scaling factor is 600% when scaling size from small to medium.
The ScyllaDB scalability results show that ScyllaDB is able to nearly achieve linear scalability by achieving a throughput scalability of 393% of the theoretically possible 400%.
The scalability results for MongoDB show that it achieves a throughput scalability factor of 262% out of the theoretically possible 600%.


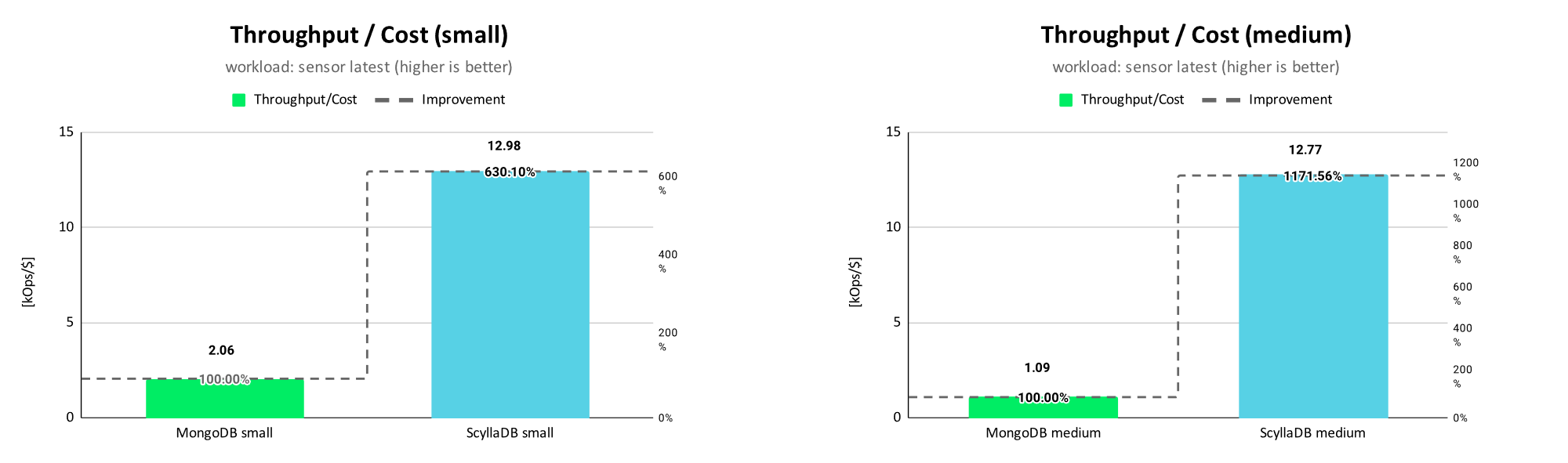
Throughput per Cost Ratio
In order to compare the costs/month in relation to the provided throughput, we take the MongoDB Atlas throughput/$ as baseline (i.e. 100%) and compare it with the provided ScyllaDB Cloud throughput/$.
The results show that ScyllaDB provides 6 times more operations/$ compared to MongoDB Atlas for the small scaling size and 11 times more operations/$ for the medium scaling size. Similar to the caching workload, MongoDB is able to scale the throughput with growing instance/cluster sizes, but the preserved operations/$ are decreasing.
Latency Results
The P99 latency results for the sensor workload show that ScyllaDB and MongoDB provide constantly low P99 read latencies for the small and medium scaling size. MongoDB provides the lowest read latency for the small scaling size, while ScyllaDB provides the lowest read latency for the medium scaling size.
For the insert latencies, the results show a similar trend as for the previous workloads. ScyllaDB provides stable and low insert latencies, while MongoDB experiences up to 21 times higher update latencies.

Technical Nugget 1 - Performance Impact of the Data Model
The default YCSB data model is composed of a primary key and a data item with 10 fields of strings that results in documents with 10 attributes for MongoDB and a table with 10 columns for ScyllaDB. We analyze how performance changes if a pure key-value data model is applied for both databases: a table with only one column for ScyllaDB and a document with only one field for MongoDB keeping the same record size of 1 KB.
Compared to the data model impact for the social workload, the throughput improvements for the sensor workload are clearly lower. ScyllaDB improves the throughput by 8% while for MongoDB there is no throughput improvement. In general, this indicates that using a pure k-v improves the performance of read-heavy workloads rather than write-heavy workloads.

Conclusion
This benchmarking study comprises 133 performance and scalability measurements that compare MongoDB against ScyllaDB. The results show that ScyllaDB outperforms MongoDB for 132 of the 133 measurements.
For all the applied workloads, namely caching, social and sensor, ScyllaDB provides higher throughput (up to 20 times) and better throughput scalability results compared to MongoDB. Regarding the latency results, ScyllaDB achieves P99 latencies below 10 ms for insert, read and update operations for almost all scenarios. In contrast, MongoDB only achieves P99 latencies below 10 ms for certain read operations, while the insert and update latencies are up to 68 times higher compared to ScyllaDB. These results validate the claim that ScyllaDB’s distributed architecture is able to provide predictable performance at scale (for more details, see the technical comparison).
The scalability results show that both database technologies scale horizontally with growing workloads. However, ScyllaDB achieves nearly linear scalability, while MongoDB shows a less efficient horizontal scalability. The ScyllaDB results were to a certain degree expected based on its multi-primary distributed architecture, while a near linear scalability is still an outstanding result. Also for MongoDB, the less efficient scalability results are expected due to the different distributed architecture (for more details, see the technical comparison).
When it comes to price/performance, the results show a clear advantage for ScyllaDB with up to 19 times better price/performance ratio depending on the workload and data set size. In consequence, achieving comparable performance to ScyllaDB would require a significantly larger and more expensive MongoDB Atlas cluster.
In summary, this benchmarking study shows that ScyllaDB provides a great solution for applications that operate on data sets in the terabytes range and that require high throughput (e.g., over 50K OPS) and predictable low latency for read and write operations. While this study does not consider the performance impact of advanced data models (e.g. time series or vectors) or complex operation types (e.g.aggregates or scans) which are subject to future benchmark studies. But also for these aspects, the current results show that carrying out an in-depth benchmark before selecting a database technology will help to select a database that significantly lowers costs and prevents future performance problems.
Appendix - Raw Benchmark Results
In order to ensure full transparency and also reproducibility of the presented results, all benchmark results are publicly available on GitHub. This data contains the raw performance measurements as well as additional metadata such DBaaS instance details and VM details for running the YCSB instances.
The structure of the repository is aligned to the structure of this report.
Appendix - Benchmarking Process
The process of database benchmarking is still a popular and ongoing topic in research and industry. With benchANT’s roots in research, the concepts of transparent and reproducible database benchmarking are applied in this report’s context to ensure a fair comparison.
When benchmarking database systems for their performance (i.e. throughput and latency), there are two fundamental objectives:
- Finding the maximum achievable throughput for different database instances
- Finding the best read and write latency for different database instances
For objective 1, the workload is executed without a throughput limitation and with sufficient workload instances to push the database instance to the maximum available throughput. In this scenario, the latency results are only secondary. Latencies are expected to fluctuate over the benchmark runtime due to the continuously high load on the database system.
For objective 2, the workload is run with a target throughput that ensures stable load on the cluster and the latency results are in primary focus. The challenge in this approach lies in identifying the required number of benchmark instances and client threads per instance to achieve the desired cluster utilization. It is noteworthy that many benchmarking tools are affected by the coordinated omission problem. In a nutshell, the reported latencies of affected benchmarking suites might report embellished latencies that are still valid for a relative comparison but might not hold for absolute latencies. The YCSB does not yet resolve the coordinated omission problem (find more details in the YCSB changelog and our reported issue). Consequently, the measured latencies should be taken with a grain of salt when it comes to absolute latencies.
In this comparison, we follow approach 2. And since the benchANT framework fully automates the benchmark process, it is very easy to run multiple benchmarks with varying workload intensities to identify the optimal throughput of each database, i.e. a constant throughput rate that still provides stable latencies. For MongoDB and ScyllaDB, this results in ~80-85% CPU cluster utilization.
The following figure illustrates on a high level the technical benchmarking tasks that are automated by the benchANT platform.
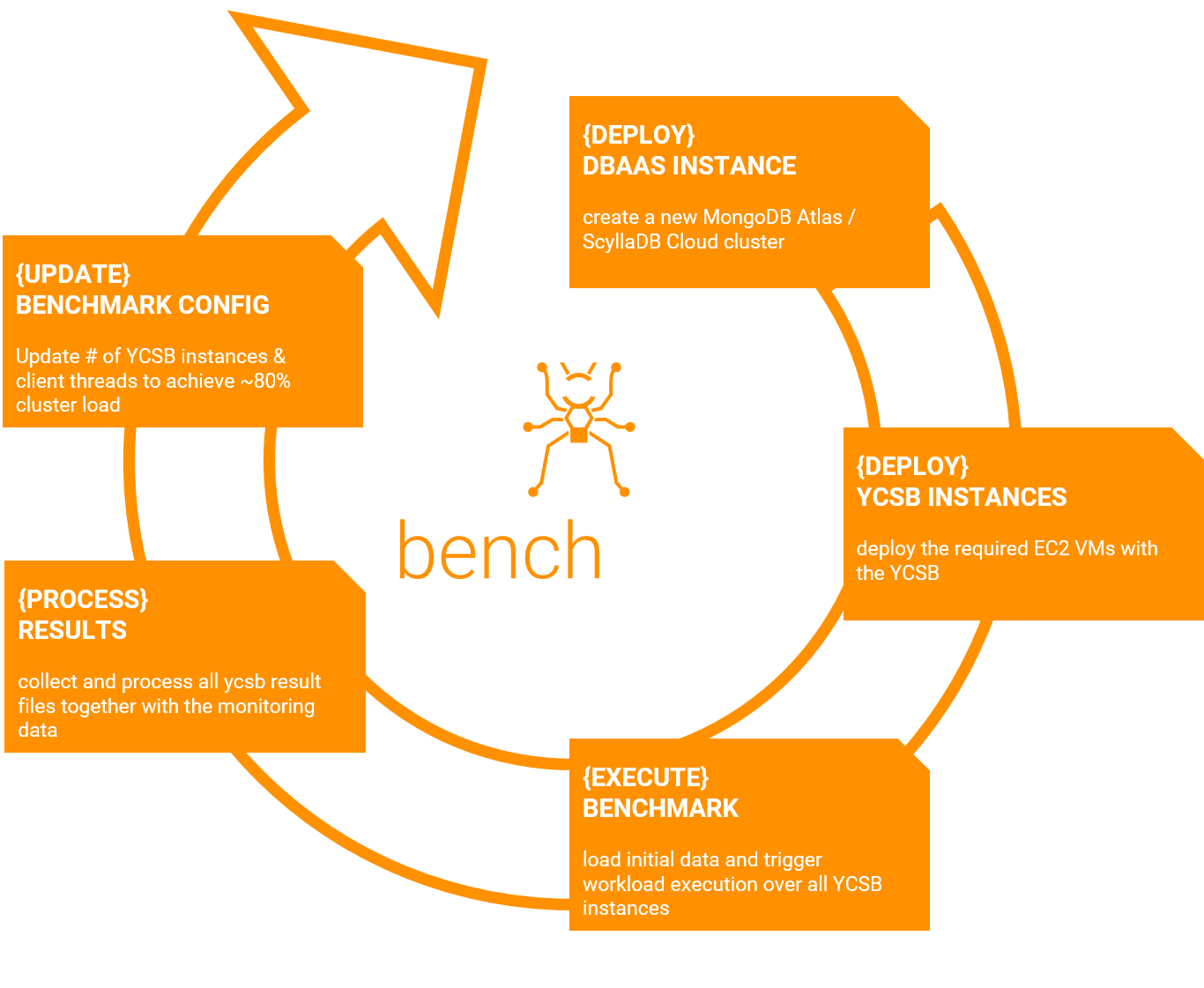
- The DEPLOY DBaaS INSTANCE step creates a new ScyllaDB/MongoDB Atlas instance based on the provided deployment parameters. In addition, this step also enables sharding on the YCSB collection level for MongoDB and creates the table YCSB for ScyllaDB.
- The DEPLOY YCSB INSTANCE step deploys the specified number of YCSB instances on AWS EC2 with a mapping of one YCSB instance to one VM.
- The EXECUTE BENCHMARK step orchestrates the YCSB instances to load the database instances with the initial data set, ensuring at least 15 minutes of stabilization time before executing the actual workload (caching/social/sensor).
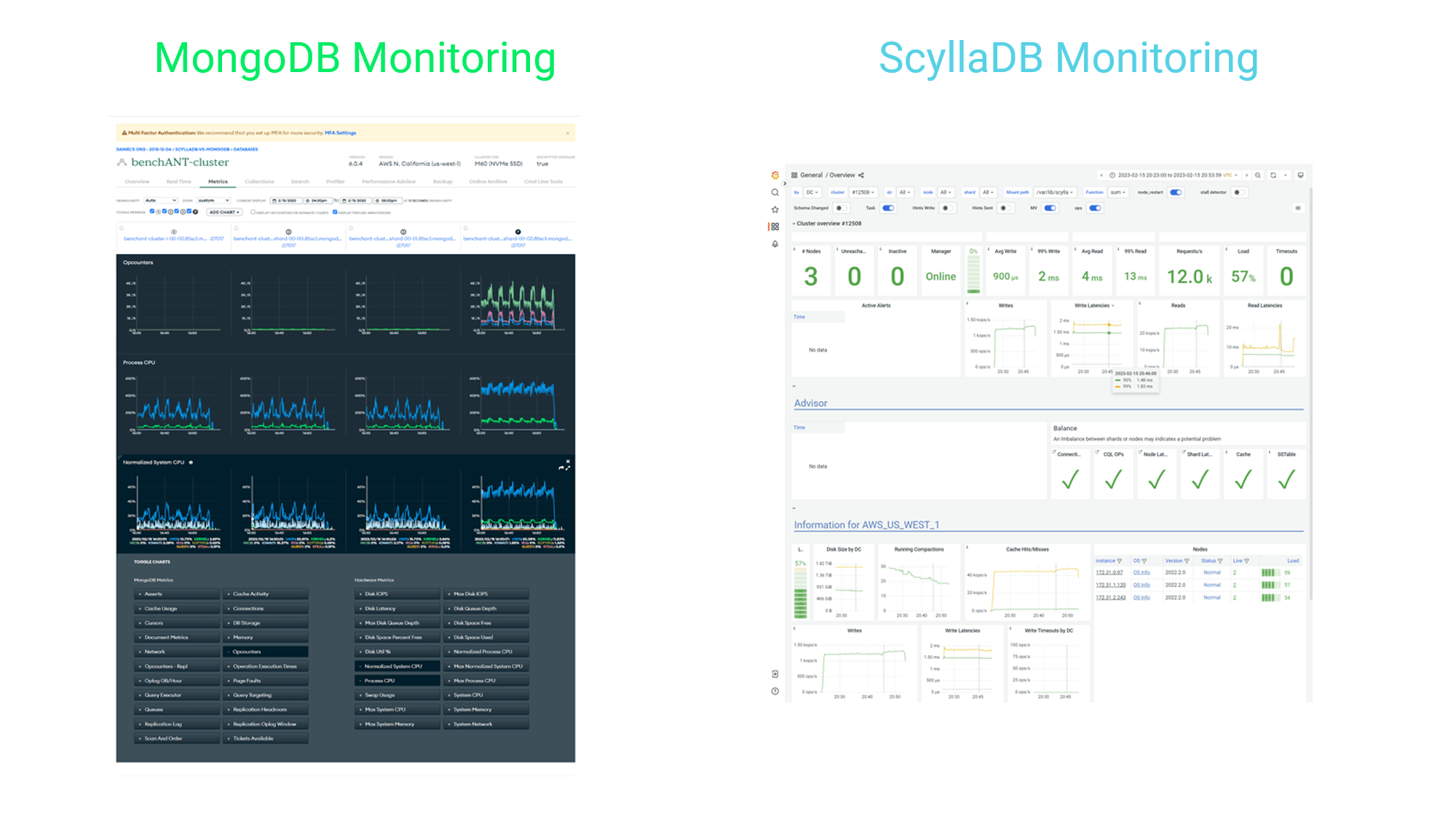
- The PROCESS RESULTS step collects all YCSB benchmark results from the YCSB instances and processes them into one data frame. In addition, monitoring data from MongoDB Atlas is automatically collected and processed to analyze the cluster utilization in relation to the applied workload. For ScyllaDB, it is currently not possible to extract the monitoring data, so we manually inspect the monitoring dashboard on ScyllaDB cloud. In general, both DBaaS come with powerful monitoring dashboards, as shown in the following example screenshots. The goal of the analysis is to determine a workload intensity for MongoDB and ScyllaDB that results in ~85% database utilization.
- In the UPDATE BENCHMARK CONFIG step, the results of the previous analysis step are taken into account and the number of YCSB instances and client threads per instance is aligned to approach the target cluster utilization.
This process is carried out for each benchmark configuration and database until the target cluster utilization is achieved. In total, we run 133 benchmarks for MongoDB Atlas and ScyllaDB to determine the optimal constant throughput for each cluster size and each workload. The full data set of the results presented in this report is available on GitHub.
Appendix - Determined Workload Intensities
Based on the outlined benchmarking process, the following workload intensities for the target database scaling size have been determined in order to achieve ~80-90% CPU utilization across the cluster:
| DB | Scaling Size | Workload | Request Distribution | YCSB Instances | Threads per YCSB instance |
|---|---|---|---|---|---|
| ScyllaDB | small | social | uniform | 2 | 100 |
| medium | social | uniform | 4 | 150 | |
| small | social | hotspot | 2 | 150 | |
| medium | social | hotspot | 4 | 300 | |
| small | caching | uniform | 2 | 125 | |
| medium | caching | uniform | 4 | 250 | |
| large | caching | uniform | 16 | 200 | |
| small | caching | hotspot | 2 | 150 | |
| medium | caching | hotspot | 8 | 150 | |
| small | sensor | latest | 2 | 100 | |
| medium | sensor | latest | 4 | 150 | |
| MongoDB | small | social | uniform | 2 | 50 |
| medium | social | uniform | 4 | 100 | |
| small | social | hotspot | 2 | 50 | |
| medium | social | hotspot | 4 | 100 | |
| small | caching | uniform | 2 | 50 | |
| medium | caching | uniform | 4 | 100 | |
| large | caching | uniform | 8 | 100 | |
| small | caching | hotspot | 2 | 50 | |
| medium | caching | hotspot | 4 | 100 | |
| small | sensor | latest | 2 | 50 | |
| medium | sensor | latest | 4 | 100 |
Appendix - YCSB Extension
During the benchmarking project, we encountered two technical problems with the applied YCSB 0.18.0-SNAPSHOT version that are described in the following.
Coordinated Omission Feature
Starting from the described coordinated omission problem in general and how we have tried to address it in this benchmarking project, there is not yet a proposed solution to the created issue on the YCSB GitHub repository.
We analyzed this problem by running not only MongoDB and ScyllaDB benchmarks with the parameter measurement.interval=both but also for other databases such as PostgreSQL or Couchbase that also resulted in unrealistic high latencies of >100s.
Due to time and resource constraints, we have not debugged the current YCSB code for further details.
Support for Data Sets of >2.1 TB
While running the scaling size large benchmarks with a target data set size of 10 TB, it turned out that the YCSB is currently limited to data sets of 2.1 TB due to the usage of the data type int for the recordCount attribute in several places in the code. This issue is also reported in a YCSB issue.
We have resolved this problem in the benchANT YCSB fork that has been applied for the ScyllaDB caching large benchmarks. The changes will be contributed back to the original YCSB repository.
About Dr. Daniel Seybold
Dr. Daniel Seybold is the co-founder and CTO of benchANT, a company that specializes in benchmarking and performance testing of databases. Daniel started his career as a researcher with a focus on distributed systems and databases. He has extensive experience in the field of database performance testing and has been working with NoSQL databases such as MongoDB, Cassandra and ScyllaDB for more than a decade. During his academic career he published over 20 papers on cloud and database performance related topics on renowned scientific conferences and completed his PhD with the thesis An automation-based approach for reproducible evaluations of distributed DBMS on elastic infrastructures.
These research results are the technical foundation of benchANT which pursues the goal of supporting organizations in selecting the right database for their use case.
From his point of view, there is no "best" database, but only a better-suited and more efficient database solution for each use case.