
What is Database Benchmarking?
Database benchmarking is a proven and clearly defined method for analysing and comparing the performance characteristics of databases or database management systems (DBMS).
Performance and scalability is a hot topic in IT. Data-driven applications and cloud infrastructures are current challenges for databases.
Database benchmarking provides reliable, quantitative answers.
Learn everything about (cloud) database benchmarking, from classic SQL databases to NoSQL and NewSQL databases in distributed cloud systems.
The Benchmarking Concept in General
In order to understand the database benchmarking methodology, it makes sense to first look at the general benchmarking framework in theory.
And then apply this to the database and cloud domains.
The general understanding of benchmarking is the measurement and comparison of various performance dimensions with industry leaders or best practice solutions according to a clearly defined methodology. Benchmarking is often used to compare business processes and technical products, especially in IT, e.g. CPU or GPU.
The methodology of benchmarking is neither new nor standardised. There are several well-known approaches with different focuses, such as SWOT analysis or potential analysis. The results are usually presented in portfolios or diagrams.
The 4 steps of the general benchmarking framework
- define your model by setting a goal, the process and your constraints.
- identify all related entities, resources, artefacts and data.
- Measure/calculate all options.
- compare the results with the identified benchmark.

Yes, this process is very generic and most benchmarking methods have a much more detailed process. But in the end it is always the above 4 steps in the order mentioned.
Because benchmarking seems so generic, but also so logical, benchmarking enjoys a high status in many areas.
Why is benchmarking important?
The aim of benchmarking is to establish a continuous improvement process to compare different solutions and create better solutions.
In many professional fields of work such an improvement process is useful and necessary. At the same time, the open generic approach usually provides quantitative results that make it possible to compare alternatives, make informed and reliable decisions and derive concrete options for action.
This is also the case with database benchmarking.
Classic Database Benchmarking
The first steps in database benchmarking were taken in the late 1980s with the advent of relational databases.
In 1993, Jim Gray published the first handbook on database benchmarking, the Database and Transaction Processing Performance Handbook. It became a kind of standard work for early performance engineering and defined the domain-specific benchmark criteria for databases.
Gray defines the goal of database benchmarks as follows:
"Which computer should I buy?".
And he gives the obvious answer: "The system that does the job with the lowest cost of ownership".
To get to that point, you need to benchmark all the options under consideration. That is, measure the performance to see if the option can do the "job" and put that performance in relation to the cost.

This guide highlights the first really important artefact for database benchmarks: the workload.
You need to know what workload your database system has to work with in order to find the most appropriate option. In the simplest case, the workload differs between Create, Read, Update and Delete (CRUD). The characteristics of these operations significantly affect the throughput and latency results of a benchmark. Transaction processing introduces another dimension to the problem space.
At the same time that Gray publishes his guidelines, the Transaction Processing Performance Council (TPC) is formed and defines benchmarks for transaction processing and database domains. The TPC is still active and defines benchmarks for modern user workload profiles.
Definition: Workload
A Workload consists of a sequence of operations issued on a database. The workload defines the variance of operations as well as access patterns. The operations may be processed by time or by sequence.
Workloads are either based on trace-based data or synthetic data, which is modeled after real-world load patterns and generated by a set of configurable constraints.
Definition: Benchmark
A Benchmark applies workloads on a database. In addition, it provides features such as metric reporting, metric processing and the coordinated execution of multiple workloads.
A single benchmark can provide different workload types that are commonly classified into OLTP, HTAP and OLAP workloads.
Here is a short list of current database benchmarks provided by the TPC:
- Application/Web Service: TPC App
- Online transactions: TPC-C / TPC-E
- Decision support: TPC-H / TPC-DS / TPC-DI
- Virtualisation: TPCx-V / TPCx-HCI
- Big Data: TPCx-HS / TPCx-BB
- IoT: TPCx-IoT
In the 1980s and 1990s, there were only a few different SQL databases: OracleDB, IBM's DB2, PostresSQL or Microsoft SQL Server. The number of possible options for benchmarking was small and the technology relatively uniform.
In the late 2000s, that changed.
Non-relational NoSQL and, more recently, NewSQL databases were developed. These had a completely different technical structure and offered different, less rigid data models; they often also dispensed with transactional functionality.
The traditional benchmarks could no longer be applied to these databases and had to be customised. Most TPC benchmarks are not applicable to NoSQL databases at all due to the heterogeneous data models and the changed API.
As the number of database providers increased, the configuration options also increased and became more customised. These factors led to an increase in complexity and effort for the database benchmarking process as well.
The website db-engines.com lists a ranking of over 370 different database systems (as of July 2021), often with multiple data models. The ranking is based on social media and search popularity BUT not on performance metrics.
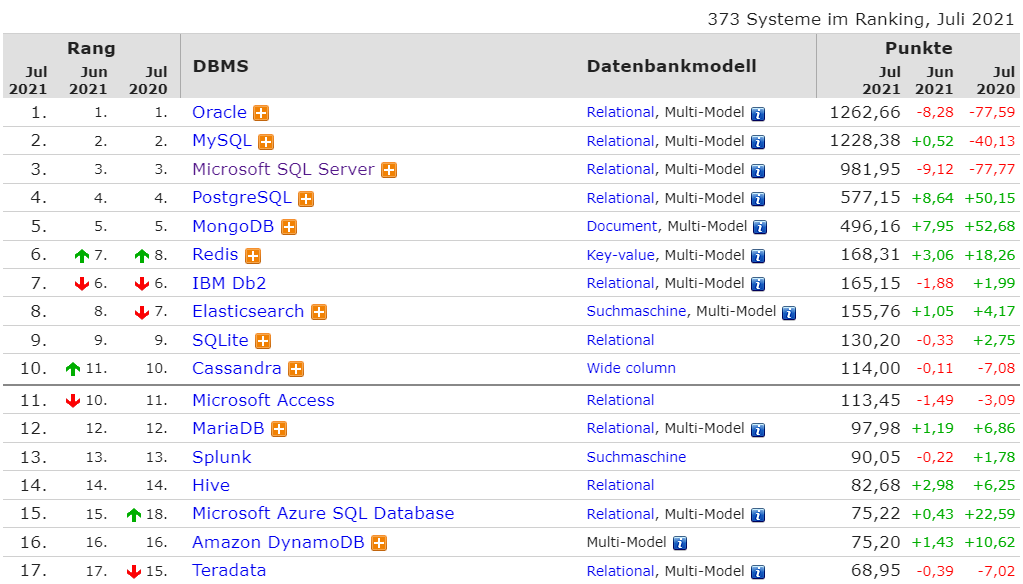
Of course, not all existing databases are suitable for a particular use case, but there are still many suitable options for most application scenarios. Most importantly, database systems have evolved that are specialised for specific use cases.
The path to polyglot persistence, where different databases suitable for the problem at hand are run in one application, seemed to be prepared. Nevertheless, many traditional relational databases still enjoy disproportionate popularity, at least if the above ranking is to be believed.
What could be the reason for this?
Are the new databases too difficult to use?
Is there a lack of experience or references?
Is there no need to switch to a more suitable solution?
What do you think?
Cloud Database Benchmarking
NoSQL and NewSQL databases developed in parallel with cloud computing. Each of these technologies is a success story in its own right, but even more so is the combination of the two. Together, they offer a high degree of flexibility and only make the multitude of new data-intensive applications in the areas of Big Data, AI, IoT, but also in eCommerce and Web 2.0 possible.
For all performance engineers and traditional database benchmarking methods, the symbiosis of the two technologies marked the beginning of a tough time. The classic benchmarks and benchmarking solutions were no longer applicable and the complexity also increased rapidly.
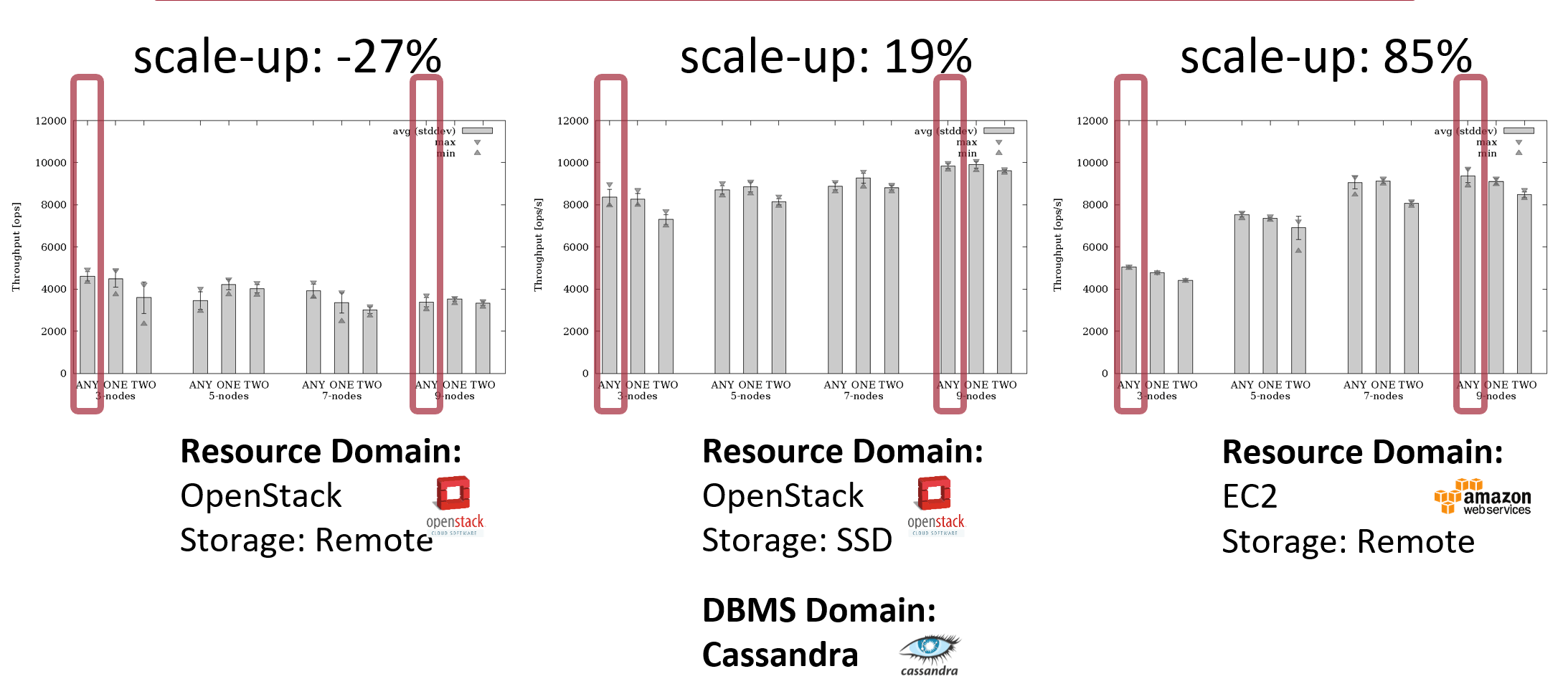
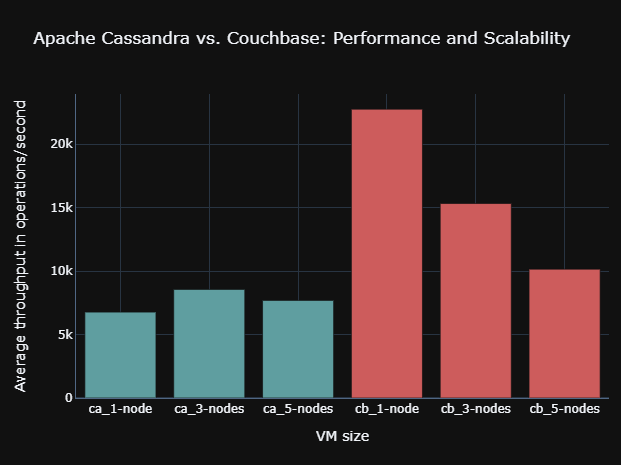
Scientific research showed that database performance can differ significantly on comparable but different cloud resources, but also cloud providers. In the following diagram, the Cassandra database was benchmarked on comparable OpenStack and AWS EC2 resources. The measured performance was different. In particular, a higher number of nodes resulted in significant performance changes.
The current Benchmarking Insight: "AWS EC2 vs Open Telekom Cloud vs IONOS Cloud" clearly shows these performance differences of the same database setup on 12 "identical" cloud resources of different cloud providers.
The 6 dimensions of cloud database benchmarking
Thus, to establish reliable database benchmarking with cloud resources, you need to look not only at the database and your workload, but also at the specific cloud provider and cloud configuration.
- Database provider
- Database configuration
- Cloud provider
- Cloud configuration
- Benchmark
- Benchmark configuration
Thus, cloud database benchmarking requires merging two previously independent performance domains - databases and cloud.
In academia, the first steps have been taken by only a few researchers worldwide in the last five years.
A few companies have developed internal scripts and workflows for semi-automated benchmarking of a few selected cloud databases.
Closing this performance engineering gap and enabling efficient use of modern database systems in the cloud is the main challenging vision of benchANT.
Besides focusing solely on performance, cloud database benchmarking also focuses on other metrics such as scalability, availability, elasticity and cloud cost. These are becoming increasingly important and must also be measured and analysed in the benchmarks.
NOTE: From this point on, "database benchmarking" always refers also and in particular to databases in cloud environments. In 2021, cloud computing and NoSQL database systems are key technologies and have become an industry standard in many areas. In the following chapters, many cloud-related topics are covered.
However, even if you are running databases in a non-cloud infrastructure, much of the following information may be useful to you and can be applied or transferred to your situation.
Uses of Database Benchmarking
So why do you need database benchmarking?
We have derived seven different scenarios in which database benchmarking can have a major impact in IT departments on decision-making and continuous optimisation.
In all of these cases, a standardised database benchmarking process enables smarter, more reliable and efficient decisions and improvements. This is true for traditional server setups and even more so for more complex cloud infrastructures.
1. Finding the Ideal Database
As mentioned earlier, the number of industry-ready databases has grown to over 350 database systems. Many of them are specialised for specific purposes, such as Time Series databases for IoT applications. For each use case, there are now at least 10 to 20 suitable competing database systems.
Which one is the best choice for your workload and cloud infrastructure? Cloud database benchmarking provides comparable measurement results, laying the foundation for objective and quantitative decision-making.
2. Finding the Ideal Cloud Resources
The second point is, of course, to find the right cloud resource for your existing or planned database and to optimise your internal infrastructure according to your requirements.
Which provider has which performance strengths and offers an optimal performance-cost ratio?
Which VM type and internal storage is suitable for your workload?
Again, database benchmarking provides the basis for an objective and quantitative decision.
3. Finding the Ideal Cloud Database Setup
As scientific research has shown and benchANTs measurements have confirmed, you cannot choose your database management system independently of your cloud provider.
This applies to all non-functional properties such as performance, availability and scalability.
The reason for this is that database benchmark results can depend significantly on the cloud provider you choose. A database may perform very well with one provider, but worse with another. And with another database or workload, it can be the other way around.
Research has not yet reached a point where reliable predictions are possible. Nevertheless, by measuring and comparing individual setups, cloud database benchmarking can reveal such correlations and identify suitable setups.
4. Noticing Performance Changes
Most database vendors release about 4 major releases per year. Cloud providers regularly renew parts of their server and service landscape. All of this can impact the performance and scalability of your setup, and not always as you would expect.
Regular cloud database benchmarking and before updating new versions will uncover such performance differences and allow you to react to them before they can affect your business processes and your customers.
5. Capacity Planning and Stress Testing
Workload requirements on cloud database setups change as businesses grow or seasonal effects such as Black Friday occur. Additionally, the limits and capabilities of current setups are often unknown.
Stress testing the current configuration to identify the limits of the current setup allows you to operate your system safely and react to changes in a timely manner.
Capacity planning also helps you to be prepared for future changes and to have suitable setups up your sleeve.
6. Tuning and "Tweaking" the Setup
Many IT departments are faced with the need to regularly tweak their database setups to reduce existing problems, work around bottlenecks or mitigate foreseen issues.
This time-consuming, error-prone and manual work of "adjusting", "observing" and "reacting" can be systematically solved by cloud database benchmarking. Finding the optimal settings takes less time, is less error-prone, is based on objective numbers - and does not have to be done in the production system.
7. Cost Optimisation through "Right-Scaling"
In the cloud, it is possible to react flexibly to changes in requirements and the environment. This freedom makes it possible to use resources efficiently as needed.
By right-scaling cloud resources, cloud costs can be reduced through smaller VMs or through fewer DB instances.
Continuous cloud database benchmarking can make this optimisation happen all the time.
There are certainly other areas where cloud database benchmarking can be used.
Can you think of other areas of application?
With an efficient, continuous cloud database benchmarking process, IT departments are able to solve daily challenges efficiently and generate technical and business added value in the company.
The Benchmarking Process in Detail
Database benchmarking has immense potential if done properly. In the following, we address the questions of what "right" means.
In particular, what steps are necessary to set up a benchmarking process and what needs to be done and considered in these steps?
For both cloud and non-cloud infrastructures, this chapter shows the necessary steps for practical implementation.
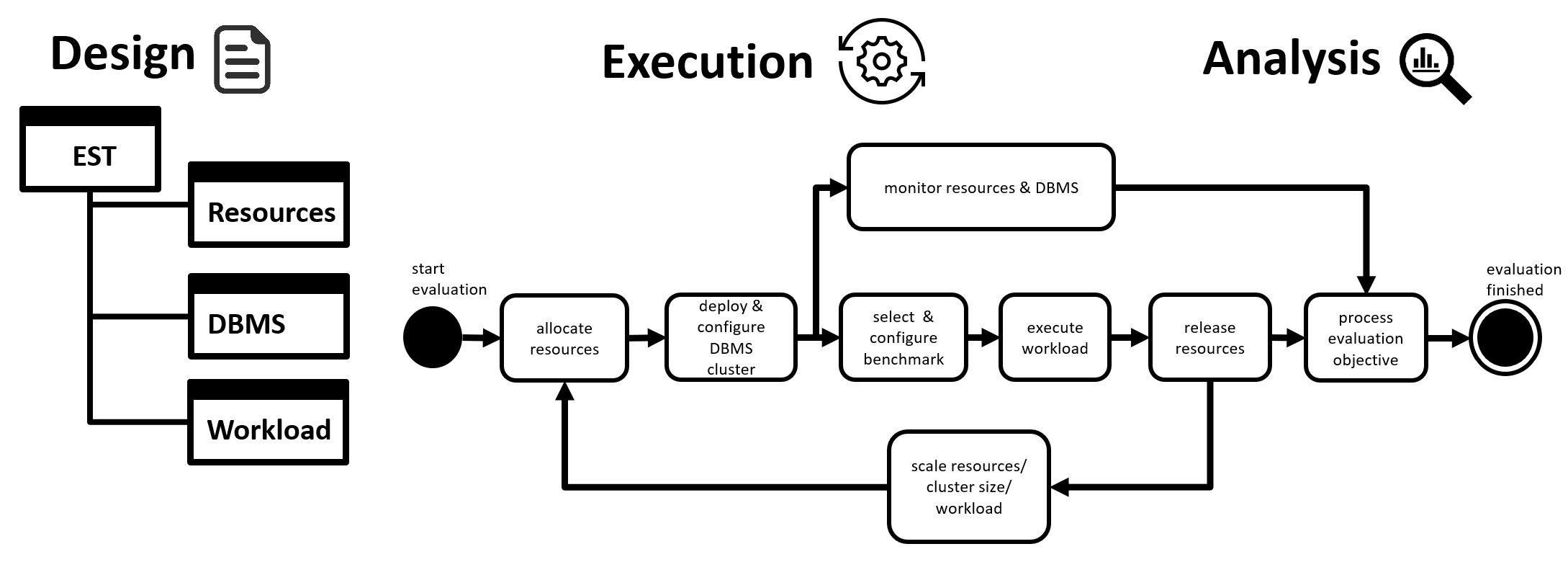
1. Design
The "Design" step includes the definition of the benchmarking objectives and the overall process design from the selection of resources, the measurement process and the analysis methodology.
The following issues need to be clarified:
- What goals such as performance, scalability, availability, elasticity and cost should be targeted?
- Which metrics need to be measured for this?
- What workload read/write distribution, number of operations, size of data elements etc. is expected or given?
- Which benchmark can be used for my workload?
- Which databases and server/cloud resources are considered?
- How is the benchmarking process structured? How often is it needed (now and in the future)? Which steps should be automated?
- How many measurements should be taken per configuration to obtain statistically reliable results?
Without experience, these questions can only be answered inadequately and are highly unlikely to deliver an optimal result. Therefore, it makes sense to approach the goal through test runs of the entire database benchmarking process in several iterations; similar to the procedure in agile software development.
There are serious differences depending on the type of infrastructure:
Non-Cloud
- The use of physical servers limits the benchmarking potential, as practically only a few servers can be tested. This refers to both the number of servers and the type of servers.
- Servers often have to be purchased based on the specifications given by a manufacturer; often the server and database are even delivered as an appliance.
- Scalability and cost are determined by the choice and quantity of servers available.
- Performance, power/dollar, power/watt are obvious KPIs. Availability can also be estimated to a certain extent.
Cloud
- The objective is much more complex and diverse due to the high flexibility and volatility of cloud infrastructures.
- The large number of cloud offerings and conceptually flexible changeable cloud resources leads to many more choices.
- To reduce the choices, a much deeper and more detailed thematic domain knowledge is required.
- Cloud resources and databases must necessarily be measured together (see above), leading to an even wider choice space.
2. Execution
The execution of cloud database benchmarking is strongly related to the decisions made in step 1. They determine the required effort and the resulting data volumes for the measured configurations. The degree of automation of the benchmarking process must be derived from this.
To avoid falsification of the measurement results, a sophisticated, non-invasive benchmarking procedure is required. Do not save the measurement results in the same database where you are currently measuring. Do not run the benchmarking software on the same resource you are benchmarking.
Non-Cloud
- Cabling, installation and setup of each server must be done manually.
- The installation and setup of each database is also done manually if it is freely selectable on the server.
- This is usually done via the command line and without a user interface. Parts of these steps can be automated by using tools such as Chef or Ansible. However, this requires the preparation of the necessary scripts in advance.
- At least a partial automation of the measurement and data preparation seems reasonable in order to efficiently obtain reliable and reproducible data.
Cloud
- Cloud resources require accounts and API keys (as well as credit card information).
- Installation and configuration of resources can be done via templates or user interfaces.
- Wiring components in the cloud is more dynamic and consequently more complicated to manage.
- Automation with cloud-native provisioning is almost mandatory to handle changing IPs and the multitude of combinations.",
3. Analysis
The third step is the analysis of the measurement results. Here, the measurement results must be statistically processed and then put into a presentation that allows the results of the different configurations to be compared.
The calculation of comparable KPIs or data visualisation is a proven approach here. The effort required for the analysis depends heavily on the objective, the number of measurement results and the distribution of the results.
Non-Cloud
- Fewer measurement configurations, fewer fluctuations in the infrastructure and a one-dimensional target variable usually make the analysis much easier.
- Visualising the results in a 2-dimensional diagram should not be a problem, if this should be necessary at all.
Cloud
- The complexity of cloud database benchmarking is also evident in the analysis phase and requires data analytics specialists who can handle large, multi-dimensional data.
- Fluctuating measurement results with outliers, multidimensional targets from multiple, different configurations need to be handled with modern data science concepts.
- A multidimensional visualisation or a complex scoring system is a crucial prerequisite for an efficient comparison.",
Cloud Database Benchmarking Challenges
In the previous chapter, some difficulties of cloud database benchmarking have been briefly addressed. However, they need more elaboration, as it is worth addressing them to understand the complexity of cloud database benchmarking.
What are these difficulties? And how do you solve them?
Iterations, Iterations, Iterations
One of the biggest challenges in cloud database benchmarking is the incredible number of nearly a billion possible configuration options. To get results in a reasonable amount of time, this huge selection space must be narrowed down in advance through knowledge acquisition and educated guessing.
But even after that, in almost no case will it be possible to compare all remaining options. In several iterative runs with "trial measurements", the set of options must be further reduced and narrowed down step by step. Only in the last iteration step does one measure and compare very similar configuration options against each other to find the optimal setup.
Cloud database benchmarking cannot completely replace thematic study and the acquisition of technology-specific knowledge about databases and cloud resources. But it can help to make a pragmatic and reliable decision in iterative runs based on meaningful metrics.
Effort for Initial Setup
Setting up a reliable, production-ready cloud database benchmarking process for the first time is daunting.
First, a lot of knowledge about databases, cloud resources and the required software implementation steps must be acquired. Then, all the desired cloud resources have to be connected and all the desired databases with their specifics have to be set up.
The effort required for these steps should not be underestimated and makes the creation of a working, reliable cloud database framework a lengthy, cross-domain software project.
Data Quality & Resilience
The benchmarking objective must make it clear what data is needed to make a decision. In addition to performance and scalability metrics, other parameters such as elasticity or availability may also be required. These requirements must be matched with data that can be measured or derived from measurements or calculated.
At the same time, the performance engineer must ensure that the measurements made for the database benchmark do not falsify the results. Non-invasive measurement methods must be used; measurements of the same configuration must also be performed more than once; and any spurious effects and statistical outliers (often a consequence of workload) must be taken into account in the analysis.
Data Preparation & Discussion
The required number of iterations, the data quality requirements combined with the number of database benchmark configurations result in a large amount of data. As mentioned, these need to be statistically processed. At the same time, the data must be prepared visually in such a way that the results are easy to grasp and can be compared and discussed efficiently.
Often it is not possible to compare the measurement data, mostly volatile time series data, in a meaningful way. Visualisation as a graph or the calculation of comparable, solid, reliable KPIs is necessary and requires knowledge in this area of data analysis. The complexity of this area should not be underestimated, as it is not a typical activity and skill of IT teams.
Continuous Market Change
Both NoSQL databases and cloud computing are key technologies that are subject to rapid change in terms of technological capabilities and market players. This volatile market makes it necessary to constantly keep up with new features and new vendors. Version updates in this technology phase can also have an extreme impact on the KPIs of the overall system, and not always in a positive sense.
Constant cloud database benchmarking makes sense in order to detect changes in the performance KPIs and thus minimise risks.
Database Benchmarking Tools & Solutions
Classic database benchmarking has existed for more than 30 years. During this time, some solutions have been developed for classic databases and non-cloud infrastructures.
In contrast, cloud database benchmarking is a new, more sophisticated field. Nevertheless, there are already first approaches and adaptations of classical database benchmarking tools:
- TPC
- YCSB
- GitHub database benchmark list
- SPEC-RG: Mowgli
- cloud database provider benchmark results
- benchANT: cloud database decision platform
Transaction Processing Performance Council (TPC)
The solution already mentioned in the first chapter is the non-profit IT consortium TPC. The TPC not only provides benchmarks (= prepared workload patterns, see definition above) for performing database benchmarks, but also publishes the benchmarking results based on them.
The consortium consists mainly of large server manufacturers such as IBM, DELL, Oracle and some IT consulting companies for performance engineering.
The published results are usually commissioned by server manufacturers and serve as a sales argument for their server database bundles, but meanwhile also partly for cloud clusters and NoSQL databases. The target metrics of these benchmarks are usually performance, price/performance and watts/performance.
The source code of the benchmarks is partly publicly accessible and can be downloaded from the website. The same applies to the results, which are available in a ranking table on the website and can also be downloaded as text files.

Yahoo! Cloud Serving Benchmark (YCSB)
Originally developed in Yahoo's research department, the YCSB benchmark is now an open-source community project.
It can now be considered the OR NoSQL database benchmark.
It has been used in several research studies and is used by many NoSQL database vendors as a basis for benchmarking white papers. Some published database benchmarking results exist on older versions of MongoDB, Cassandra, Couchbase, Apache HBase and other NoSQL databases.
Of note is the "vendor-independent comparison of NoSQL databases" article by Sergey Bushik from Altoros on Network World, which is almost 10 years old. This benchmarking project measured different workloads on different NoSQL databases on the same AWS instance and concludes that there is no "perfect" NoSQL database and that each has its advantages and disadvantages, depending on preferences. For the YCSB benchmark, 5 different default workloads were designed.
YCSB provides an important foundation for a cloud database benchmarking framework. Beyond that, it does not provide a deployable framework or a definitive solution. The YCSB benchmark is also integrated into the benchANT benchmarking platform with several customizable workload schemas.
GitHub Database Benchmark List
On GitHub there is a list of various DB benchmark results from different sources. The results mostly deal with the performance values of NoSQL databases in the cloud and in non-cloud infrastructures.
Most of these benchmark results were produced between 2009 and 2018 and should no longer be considered up-to-date. However, they can provide a first orientation for a pre-selection of suitable databases.
Furthermore, they show different approaches to database benchmarking and presentation options. This information is certainly worth a look in order to build up a stand-alone benchmarking solution.
SPEC-RG: Mowgli
The Standard Performance Evaluation Group (SPEC) is a non-profit organization dedicated to the development and management of hardware and software benchmarks. Part of SPEC is the Research Group (SPEC-RG), which is dedicated to the collaborative collection of research on quantitative evaluation and analysis techniques.
benchANT founder Daniel Seybold developed the cloud database framework "Mowgli" as part of his dissertation and made it available to the public on the SPEC-RG platform under an Apache 2.0 licence.
Mowgli provides a fully functional and stable cloud database benchmark framework. It is capable of benchmarking various NoSQL databases such as Apache Cassandra, CockroachDB or MongoDB on AWS EC2 and OpenStack instances. It supports YCSB and TPC-C as benchmarks.
At the same time, the framework is built in such a way that other NoSQL databases and cloud providers can be integrated. It also offers a rudimentary web interface and REST APIs.
Several scientific benchmarking publications have already been created and published based on the Mowgli framework. However, the Mowgli framework is no longer maintained, and it requires training and manual integration of the necessary resources. A GUI is not available.",
Database Provider Results
In the last year, some larger NoSQL manufacturers have started to develop their own database benchmarking solutions. On the one hand, these tools are used to intensively measure new versions and compare them with the results of previous versions. On the other hand, they are used to compare the manufacturer's database with direct competitors. Benchmarking white papers are published on this basis.
The publication of benchmarking results by database vendors should be taken with a grain of salt. Neither the objectivity nor the reliability of the results is guaranteed, nor is the benchmarking framework publicly accessible and verifiable. It is very likely that only selected suitable results will be published.
There are also several cloud databases benchmarking white papers from independent IT consultancies such as Altoros, which produce and publish these benchmarks on behalf of the database vendors. Again, these results should not be generalized and should be taken with a grain of salt, as the purpose of these whitepapers is also clearly marketing and sales oriented.
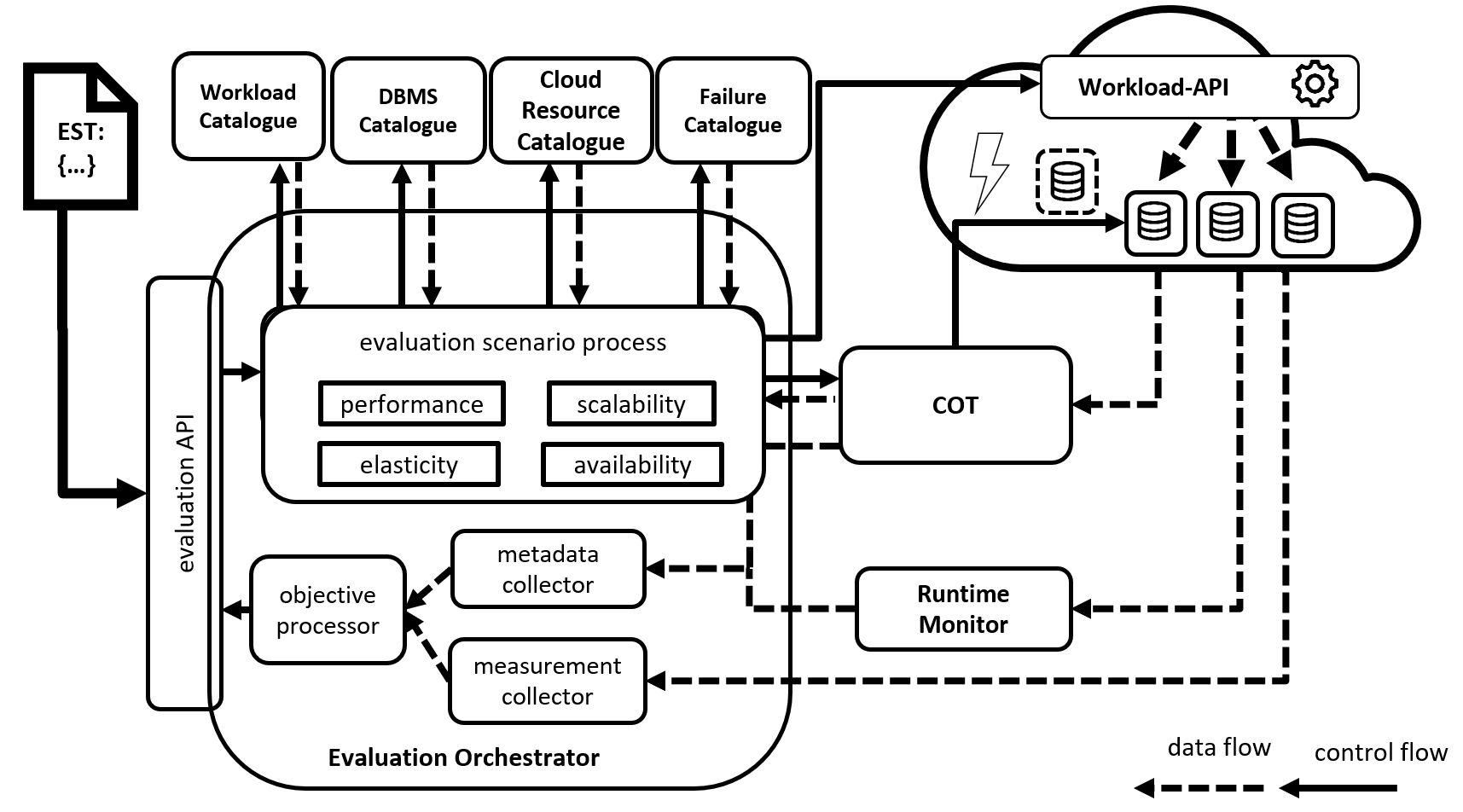
benchANT: Cloud Database Benchmarking-as-a-Service Platform
Based on the Mowgli framework presented above, benchANT is developing an on-demand cloud database decision platform that enables any IT decision maker to independently measure all available database and cloud resources against various benchmarks and interactively compare the results. A modern user interface enables the comfortable selection of cloud and database resources, the configuration of one's own workload, a fully automated measurement process and an interactive result visualization.
Several benchmark studies have already been published with the benchANT platform, such as the comparison of different cloud providers Insight: AWS EC2 vs Open Telekom Cloud vs IONOS Cloud or a large study on the two major NoSQL databases Study: MongoDB vs. Cassandra.
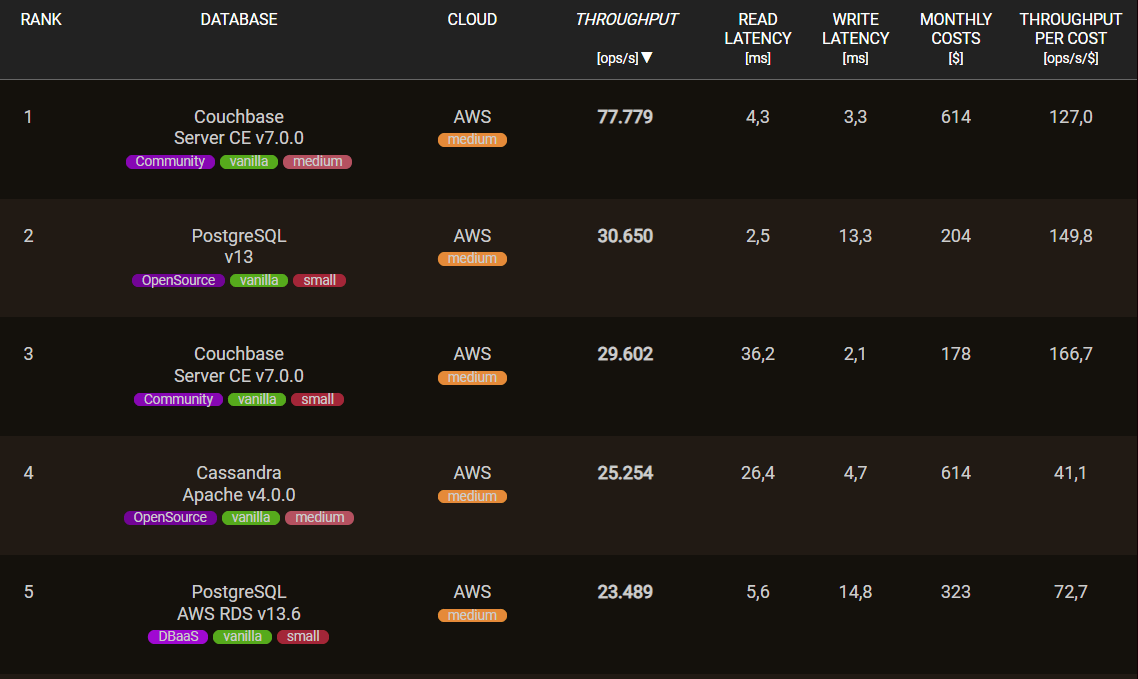
In addition, this platform provides the measurement data for the first Open Source Database Ranking, which provides performance values for numerous databases and DBaaS offerings in an objective and transparent manner.
benchANT: DBaaS Navigator
Beyond the scope of classic performance benchmarking, benchANT goes with the DBaaS Navigator for fully-managed Database-as-a-Service products. In addition to performance and a detailed price comparison, a holistic benchmarking with points and weighting is aimed at here. Thus, the dimensions "Deployment", "Management" and "Support" are additionally compared and evaluated in more than 60 data points per DBaaS product. The points can additionally be weighted according to one's own preferences in order to individually adjust the overall scoring.
This approach of classic IT performance benchmarking with attribute benchmarking with a point and weighting system, which is more familiar from business management and industry, is unique in the database sector.
Outlook & Conclusion
1. Cloud Database Benchmarking is Meaningful!
Database benchmarking has been in use for over 30 years. It enables better decisions and uncovers optimization potential. The cloud has given database benchmarking a new complexity, but also a whole new meaning. In addition to the database, the cloud infrastructure must also be measured to obtain meaningful results.
A continuous cloud database benchmarking process adds great value to corporate IT teams, reveals potential and minimizes risks. The currently widespread IT misalignment in the use of databases and cloud resources can thus be actively reduced, whereby optimizations are achieved and risks are reduced.
2. Cloud Database Benchmarking is a Cutting-Edge Challenge!
Database benchmarking is an open method - from the setting of objectives to the execution and discussion of results. This flexibility brings many open questions and uncertainties at the beginning. Extensive knowledge and interdisciplinary skills are required to design a continuous benchmarking process.
The benchmarking goals can range from performance and scalability to costs and cloud-native goals such as availability and elasticity. The pre-selection of suitable databases and cloud resources is already very time-consuming due to the large number of different providers and database products. Identifying and designing a suitable workload for a use case is a major challenge even for experienced database engineers. Creating reliable measurement data, processing and visualizing it also requires data analytical skills.
However, those who can overcome these challenges will have more reliable information to make better decisions regarding the database and cloud infrastructure, and can create significant benefits for their business.
3. Cloud Database Benchmarking is not yet well Established!
Currently, there are few current sources of information, partial solutions and published results in the area of cloud database benchmarking. There is currently no easy-to-use, publicly available software solution, nor is there a repository of current results for various DBMS.
Anyone who currently has to make a decision on the selection or optimization of a cloud-hosted database can only do so on the basis of marketing information from the manufacturers or set up their own benchmarking process at great expense. The open-source framework Mowgli can be a good basis for this. However, it also requires training and the integration of the desired database and cloud resources.
4. A Modern Solution is on the Horizon!
The benchANT benchmarking platform is already publicly available in an alpha version.
The platform offers a professional, science-based and automated cloud database benchmarking solution. Besides the easy selection of database and cloud resources and customizable workloads, the presentation of results is a core element of the platform.
Based on more than 20 years of research experience and as an evolution of the Mowgli framework, the Cloud Database Benchmarking Platform is a modern product that addresses the importance and need for better IT decisions.
Conclusion
Database benchmarking is a cutting-edge and exciting field.
There are many use cases and certainly a large optimization potential of current solutions.
What use cases and challenges do you see?
Thank you very much.