
The Data-Based MongoDB vs. Cassandra Study (2022)
MongoDB and Apache Cassandra are two of the most important NoSQL database management systems. For which use case is which DB suitable?
If you search for the differences, you will find many articles with theoretical statements about performance and scalability.
But for us, this information was not enough!
We did 18 different benchmark measurements to find out more about the performance and scalability of MongoDB and Apache Cassandra.
We are happy to share this information!

MongoDB vs Cassandra Key Insights
Brief Disclaimer: benchANT does not favor any database management system or database vendor. From our point of view there is no "best" database, but only one better-suited and more efficient database solution for each use case.
benchANT is 100% independent and analyzes database management systems using a scientifically based benchmarking framework and its automated benchmarking platform.
The key findings from our study on "MongoDB vs. Cassandra" especially regarding performance and scalability are:
1. MongoDB vs. Cassandra has been insufficiently compared to date!
Both NoSQL databases are widely used. There are numerous articles on "MongoDB vs. Cassandra", with very similar content on performance and scalability, mostly without provable data. We took measurements and dispel these myths! read more
2. MongoDB and Apache Cassandra have similar use cases!
MongoDB and Apache Cassandra cover similar use cases and customer groups. They are both "general purpose" databases that are or want to be suitable for any purpose! read more
3. Two different NoSQL databases in terms of architecture and data model!
MongoDB and Apache Cassandra differ greatly in their architecture and data model. Based on this, however, no performance statements can be made, as we measured! read more
4. Query languages yes, but very different!
While MongoDB offers its own powerful query language, Apache Cassandra only allows simple commands, but in SQL syntax-like commands (CQL). read more
5. MongoDB and Cassandra have comparable consistency levels!
Both database management systems use write-ahead logging and offer comparable consistency settings. read more
6. Cassandra has better throughput, MongoDB has lower read latency!
In the vanilla configuration, Cassandra shows higher throughput on all 3 different workloads, but MongoDB always shows lower READ latency, with the same setup and similar consistency. Both performance KPIs are of different importance, depending on the IT application! read more
7. Apache Cassandra scales well horizontally, but not linearly and surprisingly workload independent!
Scaling Apache Cassandra from 3-nodes to 6/12-nodes works almost uniformly well across all workloads. While the increase in throughput is not linear, it is within a more than acceptable range. read more
8. MongoDB scales vertically, better and worse depending on the workload!
MongoDB's good vertical scalability is clearly seen in the measurements. However, it is much better pronounced for READ-heavy workloads, while it weakens for WRITE-heavy workloads. read more
9. Scaling reduces latency on MongoDB, on Cassandra latency remains quite stable!
Vertical scaling significantly improves latencies on MongoDB. For Apache Cassandra, horizontal scaling worsens latencies only minimally. read more
Benchmark Configurations for MongoDB vs Cassandra Measurements
These findings are based on 18 professionally executed benchmark measurements with the cloud database benchmark platform benchANT. Here, various database setups were defined with the online accessible configurator and automatically benchmarked.
Database
- MongoDB (Community v.4.4.6., vanilla)
- Apache Cassandra (open-source v.4.0.0, vanilla)
- Cluster size:
- for performance: each as 3-node cluster
- for scalability: MongoDB in larger 3-node clusters (vertical scaling) and Apache Cassandra in 6/12-node clusters (horizontal scaling)
Cloud
- AWS EC2
- with NVMe Storage
- For Performance:
- MongoDB: 3x i3.xlarge (4 cores / 30.5 GiB)
- Apache Cassandra: 3x i3.xlarge (4 cores / 30.5 GiB)
- for scalability:
- MongoDB: 3x i3.2xlarge (8 cores / 61 GiB) & 3x i3.4xlarge (16 cores / 122 GiB)
- Apache Cassandra: 6x i3.xlarge (4 cores / 30.5 GiB) & 12x i3.xlarge (4 cores / 30.5 GiB)
- in the Frankfurt region (eu-central-1)
Note: i3 VMs, according to AWS, are storage-optimized instances for high read and write access to large amounts of data. They are optimized for low latency and many parallel accesses.
Workload
- simple workload with read and writes, without JOINS, aggregation or more complex queries
- 3 different READ/WRITE ratios:
- READ-heavy: 80/20,
- BALANCED: 50/50,
- WRITE-heavy: 20/80
- 3 different sizes with different number of parallel threads:
- 100 (performance)
- 200 (2x scaling)
- 400 (4x scaling)
- Access distribution: ZIPFIAN
- Workload Execution Instance: c5.4xlarge (16 cores / 32 GiB)
Why MongoDB vs Cassandra
Comparing database management systems, such as MongoDB vs. Cassandra in this case, is an essential task when planning a new data-intensive software such as e-commerce. The right database can avoid performance issues and handle sometimes large scales in data volume and workload.
MongoDB and Apache Cassandra are two of the most popular NoSQL DBMSs at the moment, as also shown by the db-engines ranking (2021/12/20).
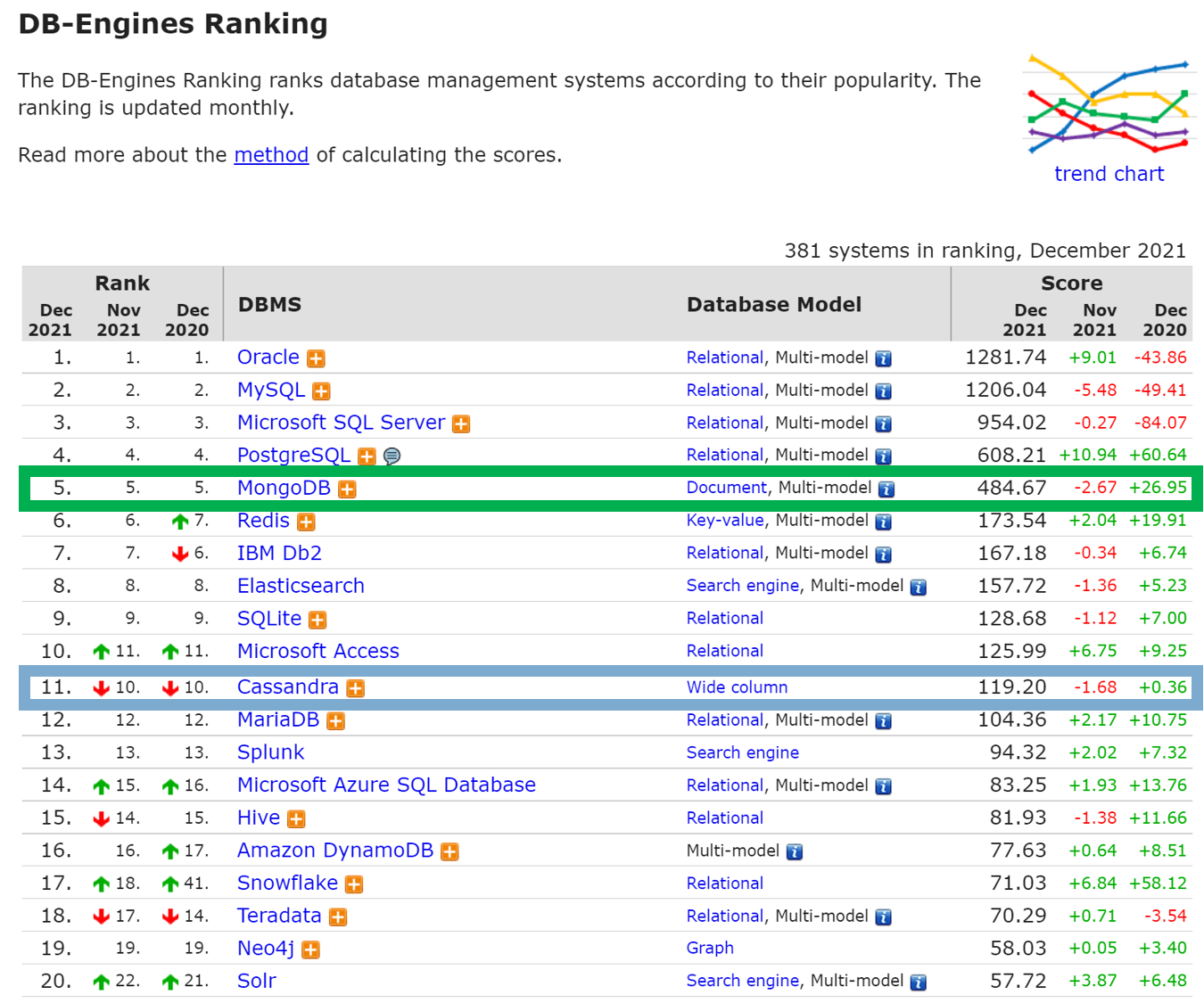
Both database management systems position themselves as “general purpose” databases, i.e., for general use for any IT applications. Both MongoDB and Apache Cassandra advertise their good performance and scalability as modern NoSQL databases.
As an IT architect, it therefore makes sense to consider the question “MongoDB vs. Cassandra”.
But if you research online for independent information, you will find about 50 blog posts that have more or less the same content and draw the same conclusions without actually substantiating them.
Interesting here are the statements about performance and scalability, which are only made on the basis of the architecture. A quantitative investigation or own tests do not take place.
A more detailed analysis does show some benchmarks with performance data. However, these are partly outdated, or were created on behalf of a DBMS vendor and most likely only consider the respective “sweat spots”.
With this study we want to provide new independent data and content!
An independent, data-based benchmarking of MongoDB vs. Apache Cassandra with current data on performance and scalability!
MongoDB vs Cassandra Use Cases & Customers
Both MongoDB and Apache Cassandra belong to the "general purpose" NoSQWL databases. They are perceived as such by customers and IT professionals and also position themselves as such. This becomes clear when analyzing the information provided on the websites about the solutions and customer success stories.
MongoDB Use Cases & Customers
MongoDB was the first commercial, industry-ready NoSQL database and paved the way for the NoSQL database success story.
But what IT applications is MongoDB suitable for?
MongoDB itself lists the following use cases, among others, on its website:
- Mobile Applications
- Internet of Things (ioT)
- Product directories
- Real-Time Analytics
- content management
- gaming
- Payments
Already through this selection one can see the "general purpose" character of MongoDB's positioning across the most important IT use cases and at the same time industry sectors.
However, IT applications from these use cases have widely varying requirements for performance metrics.
While IoT applications typically have high write intensities, while product directories and content management applications have primarily read accesses. And databases for real-time analytics applications and gaming have low read latency.
MongoDB addresses very different applications and positions itself as suitable for any use case.
The customers MongoDB lists on its website range from publicly traded global players to SaaS companies. The following list provides an excerpt of the corporate customers with their respective use cases for MongoDB.
- Forbes: company-built content management system with AI and analytics features.
- Toyota: material management software
- Otto: eCommerce platform
- Bosch: IoT Suite
- Expedia: personalized "scratchpad" for travel planning
- Sega: Mobile Games (Sonic Forces: Speed Battle)
- KPMG: Loop accounting software
And many more, see MongoDB customer list
Apache Cassandra Use Cases & Customers
Apache Cassandra as an open-source database management system has a, compared to MongoDB, significantly reduced website. Apache Cassandra does not position itself as the solution for specific industry sectors, or IT application areas, but as a scalable and fault-tolerant solution for any large data set, used by thousands of customers.
The following list provides a small sample of these customers with their intended use.
- Activision: Personalized messaging system to gamers
- AdStage: Real-time data analytics
- Apple: over 75,000 nodes for various applications
- Best Buy: eCommerce applications
- BlackRock: Investment platform
- Bloomberg: Stock index platform
- CERN: time series data
- eBay: eCommerce platform
- Instagram: social media feed
- Netflix: On-demand video platform
- Spotify: User Profile Data
- Uber: Car sharing platform
Similar to MongoDB, this results in a wide-ranging spectrum of uses and industry sectors. And the same different requirements arise in terms of READ/WRITE distribution, throughput and READ and WRITE latency.
Apache Cassandra's customer list includes some of the largest data companies in the world. These often use Apache Cassandra as the central database for their major IT products. This speaks to its great scalability and ability to handle very large amounts of data well.
So, in summary, both MongoDB and Apache Cassandra are chosen by customers for very different IT applications. Often these two databases have to cope well with many performance criteria, even with large data volumes.
MongoDB vs Cassandra Product Comparison
MongoDB Products
MongoDB has been developed by 10gen, now named MongoDB Inc, since 2010. Originally, the MongoDB database was a component of a PaaS product, which was not pursued further. Since then, the focus has been solely on the further development and marketing of the MongoDB database.
The MongoDB database engine is distributed in the following products:
1. MongoDB Community Server. The community version of MongoDB is also a source code project listed on GitHub. It is free to download and licensed under the Server Side Public License (SSPL) v1. This license was introduced by MongoDB itself. However, the Open Source Initiative does not recognize this license as "free software" or open source because certain areas of work, such as offering it as a separate service, are restricted.
The currently available "stable" community version is 5.0.6. For our benchmark measurements in this article, we still used the last optimized version 4.4.6 of the community edition.
2. MongoDB Enterprise Server
The Enterprise Server version is, as the name suggests, the commercial version of MongoDB. By taking out a subscription, you get access to advanced features such as an in-memory storage for additional throughput and better latencies, according to the promise of MongoDB Inc. The cost of an enterprise license is not listed transparently. Additional utility software rounds out the Enterprise version's offerings.
The current version of the Enterprise Server is 5.0.6.
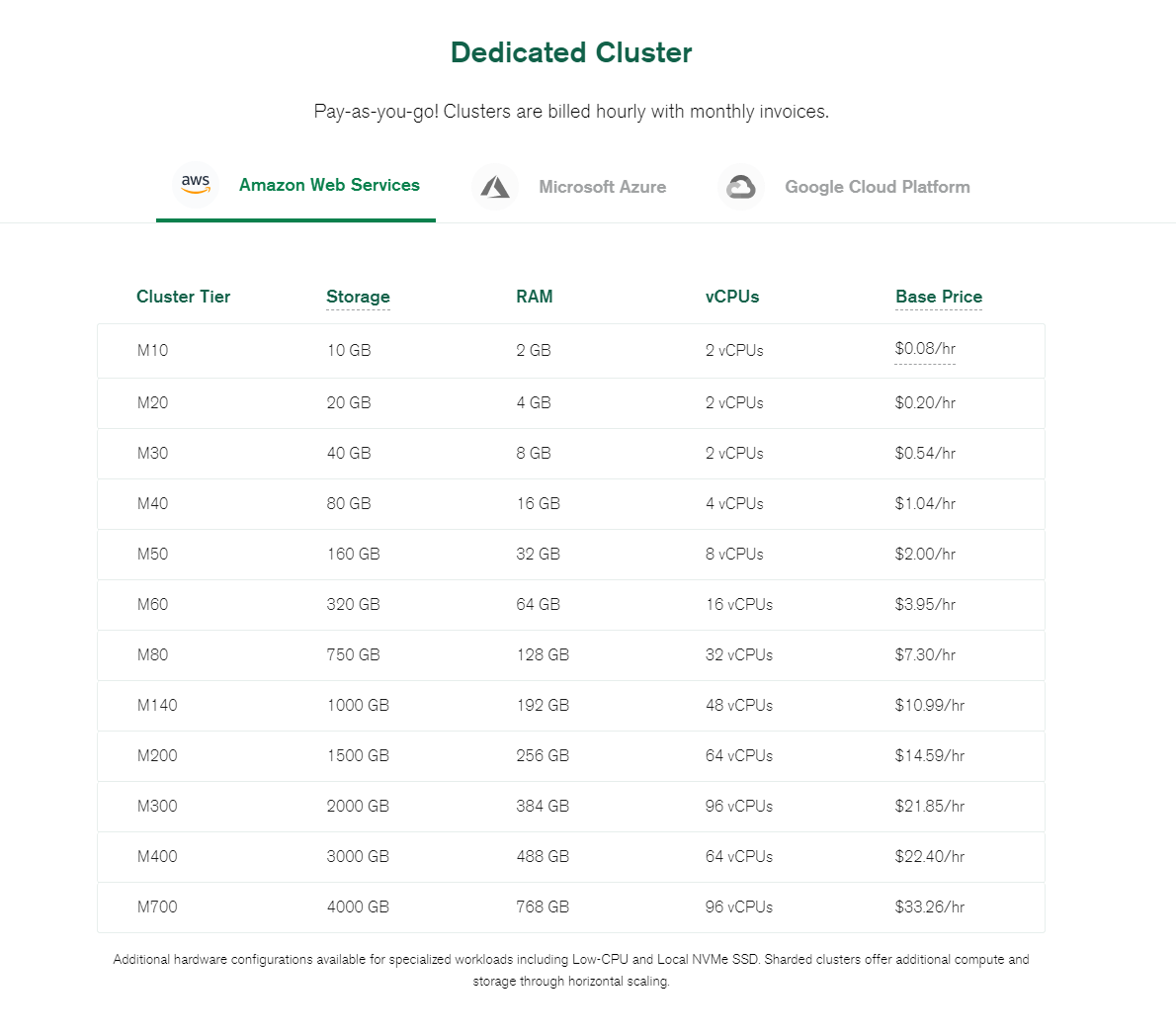
3. MongoDB Atlas MongoDB Atlas is the fully-managed Database-as-a-Service offering from MongoDB. There are 2 variants, as Serverless and as Dedicated Cluster. There are fixed product bundles that can be booked through MongoDB directly on one of the 3 major hyperscalers, AWS, MS Azure or GCP. With this product variant, MongoDB completely takes care of the installation, operation and management of the database instances. MongoDB Inc. pays for this service accordingly.
Apache Cassandra Products
Apache Cassandra started as a Facebook project and was released as an open source project in 2008. It has been an Apache Foundation project since 2009.
1. Apache Cassandra Open Source The source code of Apache Cassandra is available on GitHub as open-source under the Apache License 2.0 for free download and commercial use.
The current version 4.0.3. is also available on the Apache Cassandra page. We used version 4.0.0 for the benchmark measurements.
2. Datastax Enterprise Since Cassandra is licensed as open-source, it is also possible to offer commercial products and services based on the source code. DataStax did this in 2011 with Apache Cassandra and released an Enterprise Server version. This complements Apache Cassandra with APIs and secondary data models such as Documents, Graph and Search.
3. DataStax AstraDB DataStax has also developed a DBaaS offering that can be booked on the 3 hyperscalers, AWS, MS Azure and GCP. There are different pricing tiers depending on the number of monthly operations, storage required and support level.
4. Aiven for Apache Cassandra In addition to DataStax, Aiven also offers a DBaaS product for Apache Cassandra, which can be booked on DigitalOcean, UpCloud and OVHCloud in addition to the three hyperscalers.
5. Instaclustr for Apache Cassandra And Instaclustr also offers a managed Apache Cassandra DBaaS solution.
Cloud Clusters Managed Hosted Database for Cassandra Another provider is Cloud Clusters, which offers various DBaaS plans based on Apache Cassandra.
These DBaaS offerings are also listed in our DBaaS List with another 170 DBaaS providers with pricing model and pricing example.
MongoDB vs Cassandra Architecture
However, before we look at the performance and scalability data, let's also just briefly look at the different database architectures to understand how the previous statements were justified.
Both databases, MongoDB and Cassandra, are leading NoSQL databases designed for distributed databases and scalability. Nevertheless, the structure of a MongoDB cluster and an Apache Cassandra cluster is very different.
MongoDB Architecture
MongoDB is a distributed database and relies on a primary-secondary architecture where only the primary handles the WRITE operations and the secondaries, usually two instances, are responsible for the READ operations.
This architecture is somewhat reminiscent of classic PostgreSQL distributed architectures, with two READ instances to distribute the READ load. Indexing is done in a B+ tree (WiredTiger) that allows secondary indexes and enables fast READ operations based on the indexes.
The fixed structure of the master-slave-slave architecture does not actually allow horizontal WRITE scaling. However, MongoDB has introduced sharding that enables this horizontal scaling through additional master-slave-slave units and configuration management. However, even MongoDB itself says not to shard, but to scale vertically, through larger VMs/servers. Source: Mark Smith (MongoDB) - Everything You Know About MongoDB is Wrong!

Each sharded cluster consists of 3 components: shards, mongos and config servers. The communication and interaction of these components is complex. We will not deal with sharded MongoDB setups in the performance measurements in this article, but analyze these measurements in a separate article.
Typically, one thus scales MongoDB instances vertically through larger and more powerful VMs. MongoDB, with its primary-secondary architecture, has a significantly more complex architecture, compared to many other modern distributed database management systems.
CassandraDB Architecture
Unlike MongoDB, Cassandra does not have a master node and has a decentralized structure. All data is systematically distributed across all nodes. The distributed data is in turn replicated on additional nodes to ensure high availability.
The nodes communicate with each other via the so-called “gossip protocol”. The gossip decides where which data is written and searches for the data records during READ operations.
The architecture structure is much simpler and allows easy horizontal scalability, since additional nodes can be added easily.

MongoDB vs Cassandra Data Model
In addition to the architecture comparison of MongoDB vs Cassandra, we also briefly look at the different data models of the two NoSQL database management systems.
Decisions “pro/con” of a database are often made on the basis of the data model. This is often absurd, not only from a performance point of view! Only in a few situations is the data model really a decision criterion worth mentioning.
MongoDB data model
MongoDB relies on a document/XML data format and stores the data as BSON. The BSON (Binary JSON) is a superset of the well-known JSON format and adds additional data types to it. Each document contains a field and each field contains a value of a certain data type, e.g., an int, text, but also an array or sub-documents. Documents with a similar structure are grouped in a collection.
Document models usually require fewer JOINs, because the data is usually centrally located in a document. This allows higher performance figures, especially for large scales.
Indexes are defined per collection and are also possible over complex data structures. Collections are a collection of documents with the same structure. It is possible to create more than one collection per database.
Apache Cassandra data model
Apache Cassandra, on the other hand, relies on a wide-column store. These are data rows with a large number of key-value pairs.
Each row consists of
- a unique ID
and each column consists of
- a KEY
- a VALUE
- and a timestamp.
Similar rows are combined to a so called "Column Family" (meanwhile also called "Table"). A special feature is that not every row must have every column. This would not be possible in a relational table.

MongoDB vs Cassandra Query Language
For the practical use of a database management system, it is necessary to have a query language that allows database operations to be performed by a user or a program. There are "query languages" for this purpose. The best known is certainly the widely used "structured query language" (SQL), which is used in relational databases, but also in NewSQL and some NoSQL databases, with limitations.
There are major differences in the query language between MongoDB and Apache Cassandra.
Query Language MongoDB
MongoDB offers its own powerful query language, "mongosh" via the MongoDB shell.
This query language provides a variety of single and bulk operations for reading, writing, updating, etc. It can also be used for sub-databases. It is also possible to search/edit sub-documents / nestedJSONs and JOIN collections using the $lookup command.
The following table provides some examples of mongosh syntax compared to SQL:

The MongoDB docs also provide a helpful Mapping Chart: SQL <-> mongosh.
In addition to the MongoDB Shell commands, query operations can also be performed using the "MongoDB Compass". This tool provides a GUI for data analysis and data manipulation, which should make it easier for some user groups to work with the data.
Of course, a similar syntax exists for numerous programming languages that can also be used to execute these query operations programmatically.
The MongoDB Docs provide the corresponding syntax for the following programming languages:
- C#
- Go
- Java (sync/async)
- Engine
- Node.js
- Perl
- PHP
- Python
- Ruby
- Scala
Query Language Apache Cassandra
Cassandra Query Language (CQL) is not only reminiscent of SQL in terms of its name, but is also very similar to it in terms of its syntax.
SELECT, INSERT, UPDATE, DELETE commands with WHERE conditions can be used 1:1 from the SQL area, as well as the CREATE and ALTER commands for table operations.
However, one must be careful here regarding the dimensions, since a relational database corresponds to a Cassandra keyspace and a table to a column family. CQL does not support JOIN or GROUP BY commands. This makes it important that data should be written to column families as it will be read later.
With INSERTs there is another special feature. So records can be given a "lifetime" (here of 1337 seconds) when inserting with the command USING TTL 1337. After this "lifetime" the record will be deleted automatically. This can be useful for write-intensive applications such as IoT use cases, where the usefulness of the record is no longer given after a certain time, or it needs to be aggregated and deleted after a certain time.
Just like MongoDB, there is also a corresponding CQL syntax for Apache Cassandra for various programming languages. This is developed primarily by the commercial Cassandra provider "DataStax". The DataStax docs list the following drivers with CQL syntax:
- C++
- C#
- Java
- Node.js
- Python
MongoDB vs Cassandra Consistency
The performance of a distributed database always depends on the consistency of the data. The higher or stricter the consistency level is selected, the more internal operations a database management system must perform to ensure this consistency. These internal operations have a negative impact on latencies in particular, but also on the possible throughput, but they ensure the consistency of the data in the cluster.
Every modern, evolved distributed database management system offers settings to change the consistency level. This allows the database to be "tuned" according to one's own requirements.
It is good to know how to classify the "default" setting of the database for consistency. Comparing consistency levels across different database management systems is not easy and not possible on a 1:1 basis.
In addition to performance, the consistency level can also strongly influence the availability and error tolerance of the database management system. A precise knowledge of the consistency settings is therefore important. The consistency model of MongoDB and Apache Cassandra can be compared very well, since they both use the write-ahead logging method, as does PostgreSQL, for example. Other NoSQL databases, such as Couchbase, do not use this procedure. MongoDB calls its write-ahead logging OPLOG, Cassandra has not specified its own name for it.
With write-ahead logging, all operations are first written to a log table before the corresponding operation is executed and therefore costs a WRITE operation. However, this makes it possible to "replay" this log in case of disk failure or other failures and to restore the data accordingly. In addition, the consistency of the data can be guaranteed.
MongoDB consistency levels
In MongoDB, the levels of consistency are distinguished as "Read Isolation (Read Concern)" or "Write Acknowledgement (Write Concern)". That is, the levels of consistency can be set independently for read and write operations.
"Read Isolation" configuration options for MongoDB consistency:
- "local" (default): the record is returned from the instance with no guarantee that it was written on a majority and reset if necessary. The returned record does not necessarily have to be the most recent version of the record in the system. "local" is the default setting for primaries and secondaries in the "vanilla" setting.
- "available": Corresponds to "local" for unsharded systems. For sharded clusters it may result in a weaker consistency setting than "local", since no consultation with the "primary" is held and therefore orphaned records are returned.
- "majority": the record must be confirmed by the majority of nodes. In terms of performance, no impact should be expected as each node holds the "majority" value separately.
- "linearizable": Similar consistency to "majority" with an additional check of the primary node. This has a higher performance cost, but in certain cases also a higher consistency level.
- snapshot": A new transaction-level consistency level introduced specifically for
mulit-document transactions.
"Write Acknowledgement" configuration options for MongoDB consistencies:
- "majority" (default): as with read consistency, the record must be acknowledged by the majority of nodes.
= w: 0: No acknowledgement of the = w: 1: Data set must be written on the primary. = w: X: record must be acknowledged by primary, plus X-1 other secondaries. : Customer-specific configuration option for custom rules on which node must confirm the dataset.
For our benchmark measurements we used the "default" values "local" (read concern) and majority (write concern).
Apache Cassandra consistency levels
As with MongoDB, the consistency levels of Cassandra are separated into read consistency and write consistency. Here, however, the possible consistency level configurations are identical.
Configuration options for Apache Cassandra consistency (Read & Write):
- "ONE": Only a single replica needs to respond.
- "TWO": two replicas must respond.
- "THREE": three replicas must respond.
- "QUORUM": a majority (n/2 + 1) of the replicas must respond.
- "ALL": all replicas must respond.
- "LOCAL_QUORUM": a majority of replicas in the local data center (regardless of which data center the coordinator is in) must respond.
- "EACH_QUORUM": a majority of replicas in each data center must respond.
- "LOCAL_ONE": Only a single replica must respond. In a cluster with multiple data centers, this also guarantees that read requests are not sent to replicas in a remote data center.
- "ANY": a single replica can respond, or the coordinator can store a note. This level of consistency is only possible for write operations.
Write operations are always sent to all replica nodes, regardless of the write consistency level. This only affects the number of responses. Read operations send as many read commands as the read consistency level requires.
Here it is very easy to understand that higher consistency levels require more internal operations, which can have a significant impact on throughput and latency.
The consistency levels compare well as described and are very similar such as MongoDB's "majority" and Cassandra's "QUORUM".
MongoDB vs Cassandra Existing Performance Benchmarks
Before we present the results of our own performance benchmarks on MongoDB vs. Cassandra, we will go over existing measurement results. Often these results are produced by database vendors themselves, or on their behalf.
All benchmarks below were done with the YCSB benchmark.
bankmark - NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB, Cassandra, and MongoDB (2014).
This somewhat dated performance test from bankmark was run on on-prem resources (Dell and HP servers). Different workloads with varying READ/WRITE ratio and size are benchmarked. READ-heavy workloads yield results in favor of MongoDB, while for BALANCED and WRITE-heavy workloads, Apache Cassandra yields better throughput numbers. However, the database versions used, 2.6.5 for MongoDB and 2.1.2 for Cassandra, are outdated and probably no longer in productive use.
Altoros - Performance_Benchmark Couchbase_MongoDB_Cassandra (2018)
On behalf of Couchbase, another NoSQL “general purpose” database, IT service provider "Altoros" published the 2018 NoSQL Performance Benchmark 2018: Couchbase Server v5.5, MongoDB v3.6, and DataStax Enterprise v6 (Cassandra). Instead of the open-source Apache Cassandra version, we used the commercial DataStax Enterprise (DSE).
Similar to our benchmark study, AWS i3 instances (i3.2xlarge) were used. These were benchmarked in 4, 10, and 20-node clusters for 4 workloads, 2 YCSB + 2 custom queries. In the 50:50 workload case, DSE (Cassandra) delivered significantly better results, both in throughput and combined latency, than MongoDB. For the "short-range scan" workload (without a primary key), MongoDB delivered significantly better results. For the other two workloads, only MongoDB and Couchbase could be compared due to query complexity.
severalnines - The Battle of the NoSQL Databases - Comparing MongoDB & Cassandra (2020)
Severalnines goes into performance numbers in a MongoDB vs Cassandra blog article chapter. MongoDB is said to offer 50%, 150%, or even 25x higher performance than Cassandra, depending on the workload. However, these results are given without specification of the workload or the setup. Everyone can decide for themselves how credible such statements are.
Altoros - Performance_Benchmark Couchbase_MongoDB_Cassandra (2021)
In 2021, Altoros repeated the same benchmarking scenario from 2018 with the current versions of each database. The contents of the new comparison are quite similar to the older results. However, the exact results are already significantly different. It is not clear if this is only due to the new DBMS versions or if the workload intensity has also been adjusted.
MongoDB vs Cassandra Performance
As already mentioned in the previous chapters, many performance statements are made on the basis of the architecture without really measuring it.
But why? Performance benchmarks are (usually) time-consuming and technically demanding.
But not with benchANT! With us, benchmarks are convenient and fast - thanks to our automated benchmarking configurator.
We have measured the performance of MongoDB vs. Cassandra in detail. First with the vanilla database configuration, for all 3 workloads executed above (READ-heavy, BALANCED, WRITE-heavy) and then in a second step scaled sizes, see chapter "Scalability".
What is the performance of each database?
How dependent is the performance on the applied workload?
And how accurate are previous statements?
MongoDB vs Cassandra: Performance Benchmarks - Vanilla
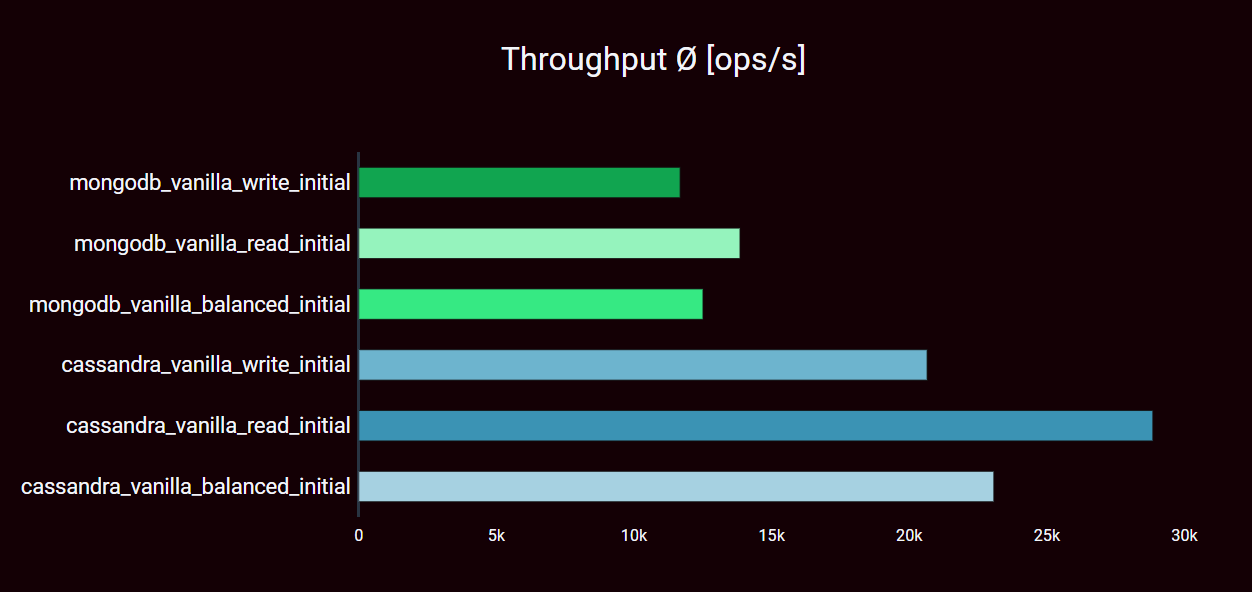
In the vanilla configuration, with the specified workload specifications for all workload scenarios, the picture is clear. The measured operations per second are mostly higher for a READ-heavy workload than for write-intensive workloads. This is common and expected, as read operations are more efficiently possible for most database management systems.
Throughput
READ-heavy workload
- MongoDB: 13.849 ops/s
- Cassandra: 28,847 ops/s
BALANCED workload
- MongoDB: 12,504 ops/s
- Cassandra: 23,072 ops/s
WRITE-heavy Workload
- MongoDB: 11,673 ops/s
- Cassandra: 20,647 ops/s
Cassandra manages almost 1.75x as many operations per second for the WRITE-heavy workload, and even twice as many operations per second for the READ-heavy workload. With the same resources used and a comparable consistency level, which has a big influence on the performance, this is an amazing result.
However, the picture for the latencies is much more differentiated. We always look at the 95% percentile - this means that 95% of all data sets could be written or read faster.
WRITE latency (95% percentile)
READ-heavy workload
- MongoDB: 65.3 ms
- Cassandra: 8.6 ms
BALANCED workload
- MongoDB: 36.7 ms
- Cassandra: 9.8 ms
WRITE-heavy workload
- MongoDB: 26.3 ms
- Cassandra: 11.6 ms
READ-Latency (95% percentile)
READ-heavy workload
- MongoDB: 6.5 ms
- Cassandra: 8.2 ms
BALANCED workload
- MongoDB: 5.3 ms
- Cassandra: 11.2 ms
WRITE-heavy workload
- MongoDB: 4.8 ms
- Cassandra: 12.7 ms
In terms of READ latency, which is much more relevant in most use cases, there are clear advantages for MongoDB. READ latencies in the range around 5 ms are outstanding. Apache Cassandra takes almost twice as long to read records.
With the WRITE latency, it looks different again. MongoDB's values are not even close to convincing. However, the WRITE latency is not crucial or critical in this order of magnitude in many applications.
In summary, it can be stated that the frequently described advantages in read operations for MongoDB are only half the truth. It clearly shows in latency, but not in throughput. In the “MongoDB vs. Cassandra” comparison, there is no clear winner in terms of performance, because high throughput is more important for some applications, and low latency for others.
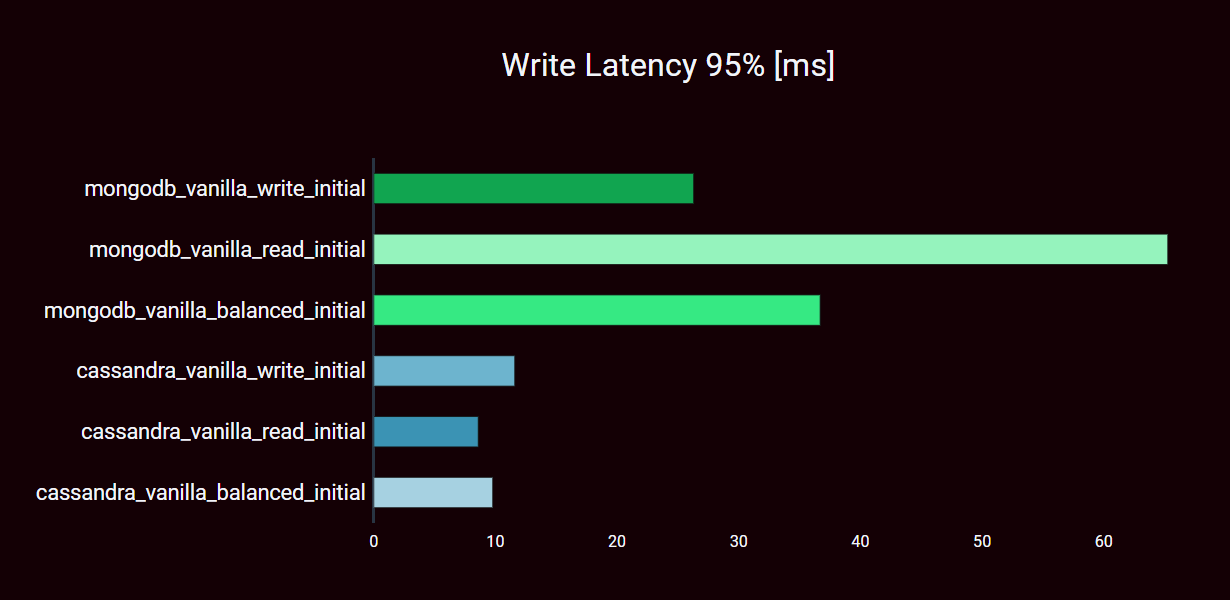
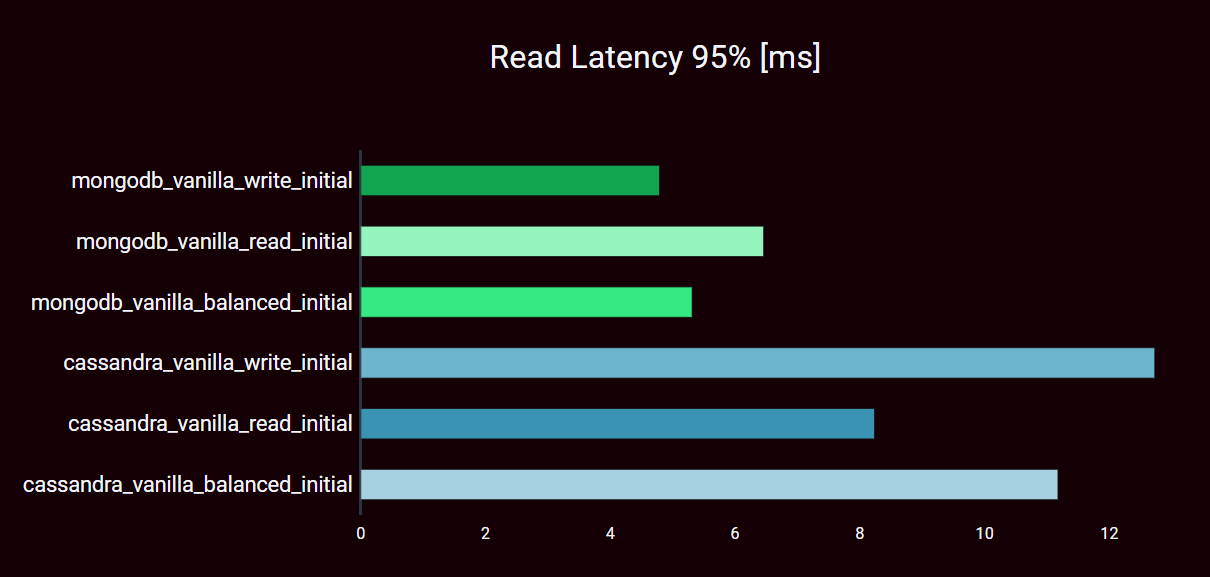
The vanilla configurations of the two databases compare well in terms of their consistency level. With MongoDB, each record must be written to disk on at least one secondary. For Apache Cassandra, the consistency is ONE. This represents a roughly comparable consistency strength.
In the performance measurements, the CPU utilization of the virtual machines was about 70% for both MongoDB and Cassandra, and that of the workload instance was about 30-50%. These values indicate an ideally scaled workload for the selected resources. No instance was in overload, but always a reasonable workload range.
Most read operations were in-memory operations due to the selected size and read distribution (Zipfian). For disk-bound operations, of course, performance can be different. In the case of Cassandra, 75% of memory was allocated for memory by configuration; in the case of MongoDB, there is no corresponding configuration parameter.
The simple CRUD workload of the YCSB selected here certainly does not recreate a real application, but it does allow a good initial comparison.
But what about more complex workloads?
MongoDB in particular can handle much more complex data structures and database operations than the YCSB can deliver.
More detailed and realistic benchmarks can be performed, for example, with the Genny benchmark suite. This makes it possible to recreate real-world load patterns and database setups and optimize them through benchmarks. There is also an appropriately tailored benchmark suite for Apache Cassandra, tlp-stress.
These 2 benchmark suites are well suited for realistic optimizations through benchmark measurements for right-sizing, cloud cost optimizations as well as database tuning. However, they do not allow comparison of different databases against each other.
MongoDB vs Cassandra: Performance Benchmarks - tuned
However, the performance of databases in the vanilla configuration is only meaningful to a limited extent.
Many databases offer numerous options for fine-tuning the database according to its intended use. This can result in better performance, in terms of throughput or latency. In some cases significant improvements can be made, but in others the effect is very limited.
Apache Cassandra, for example, has 110 parameters that (can) influence performance. Also MongoDB offers some tuning parameters to fit the needs as good as possible. With MongoDB, the performance can also be improved by changing the data model or critical queries.
For a professional tuning, 2 approaches are useful:
- professional, experienced experts who know the respective database management system down to the last detail and have made numerous experiences in the most diverse use cases. These experts are of course rare and charge corresponding hourly rates.
- the second approach follows the “try & watch” principle. By systematically changing individual parameters and analyzing the effects, an ideal configuration can be determined. Of course, the “Try & Watch” principle should NEVER be applied to the production system. Load tests on test systems are ideal for this.
Of course, the two approaches can also be combined to get by with experience and fewer measurements.
This is exactly the approach we would like to try out: We are looking for experts to jointly find an ideal tuning through benchmarking. For this purpose, we offer the free use of our cloud database benchmarking platform. Hereby it is possible to easily vary a variety of database settings, measure and compare the performance of this configuration.
If you are a Cassandra or MongoDB expert and are interested in contributing here, please contact us with reference to this article.
Note: In general, database tunings should never be done untested in a production system. They can have not only positive, but also extreme negative effects on the performance and stability of the production database management system and the IT application on top of it. Tuning parameters should be evaluated through structured testing and only then transferred to the production system.

MongoDB vs Cassandra Scalability
As already indicated in the architecture chapter, MongoDB and Cassandra are usually scaled differently to handle increasing requests and data volumes. MongoDB can only be scaled vertically, i.e. through larger virtual machines, if one does not want to sharden.
Apache Cassandra, on the other hand, recommends scaling horizontally by adding more of the same instances.
We consider the following 3 scaling sizes to make an assessment of scalability:
- Initial: 3x i3.xlarge instances (4 cores x 30.5 GiB).
- 2x scaling
- MongoDB: 3x i3.2xlarge (8 cores x 61 GiB)
- Apache Cassandra: 6x i3.xlarge instances (4 cores x 30.5 GiB)
- 4x scaling
- MongoDB: 3x i3.4xlarge (16 cores x 122 GiB)
- Apache Cassandra: 12x i3.xlarge instances (4 cores x 30.5 GiB)
Thus, we give MongoDB and Cassandra the same compute power at each scale size, just split differently. Of course, the setups, technically, are not identical, and 1:1 comparable, because MongoDB still has only 3 (larger) storage disks and Cassandra has an increased required network communication due to the high number of nodes.
In order to test the scalability in a meaningful way, we scale the workload accordingly:
- Initial: 100 parallel threads
- 2x scaling: 200 parallel threads
- 4x scaling: 400 parallel threads
Without adjusting the workload, the throughput numbers would only increase disproportionately. The instance responsible for running the workload was not changed. However, monitoring was done to ensure that the workload was never at a limit.
Cost Comparison - Scaling MongoDB vs Cassandra.
The on-demand prices of the setups, extrapolated to one month, are as follows:
- Initial: 3x i3.xlarge instances: $551.88
- 2x scaling
- MongoDB: $ 1,103.76
- Apache Cassandra: $ 1,103.76
- 4x scaling
- MongoDB: $ 2,207.52
- Apache Cassandra: $ 2,250.36
In this case, the type of scaling makes (almost) no difference from a cost perspective, as AWS prices its i3 instances very linearly. However, it is often observed that horizontal scaling is cheaper than vertical scaling. This is especially true for larger VMs, but varies from case to case.
Cassandra: Benchmarks scalability
In our example, Apache Cassandra is scaled horizontally, i.e. we expand the initial setup (3-node, i3.xlarge) to a 6-node cluster and to a 12-node cluster. In parallel, we also double the workload in each case.
Ideally, the throughput should then also double in each case and the latency should remain as stable as possible.
For the throughput of Cassandra, we see the following scaling factors:
- 3-nodes ➔ 6-nodes: scaling factor 1.7-1.8
- 6-nodes ➔ 12-nodes: scaling factor 1.57-1.65
On the one hand, this means that doubling the resources for a doubled workload does not result in doubled performance. Cassandra gains 70-80% additional throughput at this initial resource doubling.
Second, even at this scaling, one sees diminishing marginal utility. A further doubling of resources (to 12-nodes) already brings 13-15% less performance gains. The throughput increases by approx. 60% in this scaling step, depending on the workload.

For the latencies, one ideally hopes for a consistently low size with increasing scaling. Therefore, a small scaling factor is much more desirable here.
WRITE latency
- 3-nodes ➔ 6-nodes: scaling factor 1.1-1.27
- 6-nodes ➔ 12-nodes: scaling factor 1.12-1.15
READ latency
- 3-nodes ➔ 6-nodes: scaling factor 1.13-1.15
- 6-nodes ➔ 12-nodes: scaling factor 1.12-1.16
An increase in the range of 10-15% for the latencies can be considered a good value. Only the increase of almost 27% in WRITE latency for the BALANCED workload is noticeable. All other values are stable at a reasonable level.


MongoDB: Benchmarks Scalability
As mentioned, MongoDB can also be scaled horizontally through "sharding", but we will initially focus here on vertical scaling with larger VMs in a 3-node cluster.
If you are interested, we will look into "MongoDB sharding" in another article and run suitable performance benchmarks.
For throughput, we see the following scaling behavior from MongoDB:
- i3.xlarge ➔ i3.2xlarge: scaling factor 1.83-2
- i3.2xlarge ➔ i3.4xlarge: scaling factor 1.5-1.8
The READ-heavy workload in particular scales excellently with MongoDB. We even saw a doubling of throughput here with the first resource doubling.
As with Cassandra, we see diminishing benefits in the second scaling stage. Here, the differences in the throughput values are now already clear. While the READ-heavy workload scaled by 3.6 times from 13,800 ops/s to over 50,000 ops/s, the throughput of the WRITE-heavy workload only grew by 2.75 times from 11,600 to 32,000 operations per second.
MongoDB makes up quite a bit of ground to Apache Cassandra when it comes to scaling. Nevertheless, the measured throughput values are always smaller than Apache Cassandra.

In the scaling behavior of the latencies, we see a very differentiated behavior.
WRITE latency
- i3.xlarge ➔ i3.2xlarge: Scaling factor 0.38-0.58
- i3.2xlarge ➔ i3.4xlarge: scaling factor 0.59-1.0
READ latency
- i3.xlarge ➔ i3.2xlarge: scaling factor 1.44-1.7
- i3.2xlarge ➔ i3.4xlarge: scaling factor 1.0-1.5
The initial high WRITE latencies move to a much lower level due to scaling, which can be compared to Apache Cassandra. In particular, for the READ-heavy workload, the WRITE latency improves by more than 4x. This development is amazing, apparently larger resources do amazing things here and work much more efficiently and faster despite the equally increased workload.
The measured READ latencies in the original resource size were outstanding. Unfortunately, these latency sizes increase sharply with increasing workload and resources (in some cases). The measured READ latencies grew 44-70% at the first scaling along. At the second scaling, READ latency even remained stable for READ-heavy workload, while it increased by another 50% for WRITE-heavy workload.
The dependency of the specific workload is again clearly visible here. The READ-heavy workload stabilizes faster and scales better than the WRITE-heavy workload. This strongly workload-dependent behavior was almost not seen at all in Cassandra.
Mainly in terms of latency, the comparison of “MongoDB vs. Cassandra” lags immensely due to the different scaling types. MongoDB was able to reduce latencies with the same number of nodes and larger VM resources, despite increased workload and increasing data volume. With Apache Cassandra, they grew slightly, but remained in an acceptable, stable range.


MongoDB vs Cassandra Conclusion
The study shows once again that one should not draw conclusions about performance results or even scaling behavior based on architecture or data models. It seems that many articles, even from reputable sources, have picked up existing opinions about performance without their own measurements, without verifying them.
Through our measurements, we were able to measure the strengths of MongoDB and Apache Cassandra at 3 different workloads and 3 different scale sizes and provide provable data.
Is the IT application workload more WRITE-heavy or READ-heavy?
Is throughput or READ latency or WRITE latency more important to the IT application?
Some very interesting behavior could be measured and at the same time also shown that every database has a right to exist.
MongoDB itself says “Assume nothing, measure everything!”. In this sense, we are very pleased to have again dispelled some existing performance myths in the database universe and to have delivered facts.
But who knows? How would it look with other workloads, e.g., with more complex queries, or other data set sizes? Or with different database configurations, or cloud resources?
Every IT application is unique, and for every application there are more technically-suitable, efficient and cost-effective setups, but also setups and technologies that are less suitable!
With a study, with fictitious workloads like in this comparison of “MongoDB vs. Cassandra”, or random googling you will not find an answer to your individual problem.
Please measure yourself for your requirements, your workload, and your scale size!