
How-to: A Starting Point for PostgreSQL Configuration Tuning
There is always a lack of information and expertise regarding database configuration parameters. Tuning databases for specific use cases and workloads usually requires experience.
In this article, we show you how to start with database tuning and some alternative methods instead of hiring high-paid database consultants but still get better performance from your data infrastructure.
Table of Contents
- Chapter 1: Key Insights
- Chapter 2: 5 Ways How-To-Do Database Tuning
- Chapter 3: PostgreSQL Configuration Benchmarking - Results
- Chapter 4: Summary
- Appendix
Key Insights – Database Configuration Tuning
- Database parameter tuning is the process of optimizing the database configuration for your workload.
- The database technology documentation, the community and selected experts provide information, tips, and ready-made configuration files.
- Individual configuration parameters are often dependent on further parameters or influence each other.
- Database benchmarking helps to evaluate new configurations and compare them with the old configuration.
- PGTune is a well-known community tool for PostgreSQL tuning. We used it to create a tuned configuration for data warehouse / OLAP workloads.
- The measurement results compared to an untuned vanilla PostgreSQL were amazing.
- For write-heavy workloads, performance advantages of 20-30% were achieved. However, we could not measure any improvements for read-heavy workloads with our configuration.
5 Ways How-To-Do Database Configuration Tuning
Database parameter tuning is about creating an ideal configuration for your installation, your workloads, and your specific requirements.
The aim is often to increase the performance of the database and make the most important database statements execute faster.
Many databases offer numerous parameters for internal caching, replication, backup, and parallelization. The number of parameters can be well over 200 and the number of possible variables is endless. However, the interaction of different parameters must also be taken into account, as some variables only have a noticeable effect in combination with other settings.
Yet, setting parameters falsely can also lead to significant performance losses and even corruption of the database. This is the reason why many database administrators leave settings at default values and do not take a closer look at this topic.
In the next 5 sections, we present different possibilities for database parameter tuning and subsequently show the impact of such tuning.
Parameter “Playing”
The first starting point for tuning is the database documentation. Here you will usually find an explanation of the individual parameters and variables. Depending on the quality of the documentation, in-depth information and correlations to other parameters are already provided here.
Often, based on this information changes are made to the production system. We strongly advise against this approach, as it can quickly lead to the problems described above.
Community Solutions
Based on an understanding of the documentation on the configuration parameters, we recommend at least searching the community blogs and tools for helpful solutions. The well-known open source databases in particular offer a sufficiently large community for this.
However, the problem here is often not finding sufficient information on your workload and your top queries, but only on "similar" requirements. In our tuning case, we chose the well-known PGTune for PostgreSQL, which at least uses the workload type and other meaningful requirements as input parameters to create an improved configuration.
Database Consultants
A much more professional solution is provided by dedicated database experts who have in-depth knowledge of the respective database technology and have already optimized many database installations.
However, this solution also requires a sufficient understanding of the database workload and the most important queries. This understanding must be developed by the database consultant and transformed into the parameters.
This solution is certainly not the cheapest, but with an experienced and high-quality consultant, it promises a satisfactory and secure result for the production database.
Auto-Tuning Tools
Machine learning and AI do not stop at database configurations. In recent years, numerous tools have appeared that promise precise automatic tuning of the database by understanding the workload over time. We recently wrote an article about 3 such auto-tuning tools.
So far, we have been unable to prove the promised performance improvements in individual short benchmarking tests. Expensive long-term measurements would probably be required to prove this.
Of course, using such an approach raises the question of how good the tool is and how high the risk is of selecting "bad" configurations in the production system.
Database Configuration Benchmarking
Of course, a company that specializes in database performance measurements also suggests such measurements for configuration tuning. However, this is also the prevailing scientific opinion.
Different configurations can be measured for a modelled or traced workload, which is modelled on the production system, and the effect of the parameter changes can be tracked down to the query level.
In the following chapter, we have example measurements that show the advantages of benchmarking in configuration tuning.
PostgreSQL Configuration Benchmarking Results
We are once again using PostgreSQL, one of the most popular database technologies, to demonstrate the usefulness of database benchmarks for configuration tuning. Our starting point here is the documentation and the community tool PGTune, which we briefly introduce below.
For four fundamentally different workloads, we show the benefits of tuning, but also why it makes sense to benchmark the effect of configuration changes.
PGTune – A Starting Point for PostgreSQL Tuning
Regarding PostgreSQL configuration tuning, a good starting point is the open-source community tool PGTune.
The most important parameters for tuning must be specified in PGTune:
- The DBMS version
- The application load (workload)
- RAM, CPU, and storage
From this, PGTune calculates the variables for 17 important tuning parameters, see also our PostgreSQL DBaaS tuning article.
The results can be copied to the postgresql.config file to replace the default settings for these parameters.

We used PGTune to optimize our system for a data warehouse (OLAP) use case.
PGTune provides the following configuration parameters, compared to the default settings for this:

| PostgreSQL Configuration | Default/Vanilla | PGTune Config |
|---|---|---|
| shared_buffers | 1.3GB | 8GB |
| effective_cache_size | 4GB | 24GB |
| maintenance_work_mem | 65MB | 2GB |
| checkpoint_completion_target | 0.9 | 0.9 |
| wal_buffers | 16MB | 16MB |
| default_statistics_target | 100 | 100 |
| random_page_cost | 4 | 1.1 |
| effective_io_concurrency | 1 | 200 |
| work_mem | 4096kB | 41943kB |
| min_wal_size | 80MB | 1GB |
| max_wal_size | 1GB | 4GB |
| max_worker_processes | 8 | 8 |
| max_parallel_workers_per_gather | 2 | 4 |
| max_parallel_workers | 8 | 8 |
| max_parallel_maintenance_workers | 2 | 4 |
As you can see PGTune recommends allocating more RAM for buffering, caching and internal workers. It also recommends changing the random_page_cost an internal calculation value for query costs, and also to increase other worker and WAL settings.
This configuration is used in benchmarks for 4 different workloads against the default configuration of PostgreSQL:
- YCSB – A: CRUD workload with 95% read and 5% update queries
- YCSB – B: CRUD workload with 50% read and 50% update queries
- TPC-C: OLTP workload
- TPC-H: OLAP workload
The complete workload and benchmark settings are listed in tabular form in the appendix
Throughput

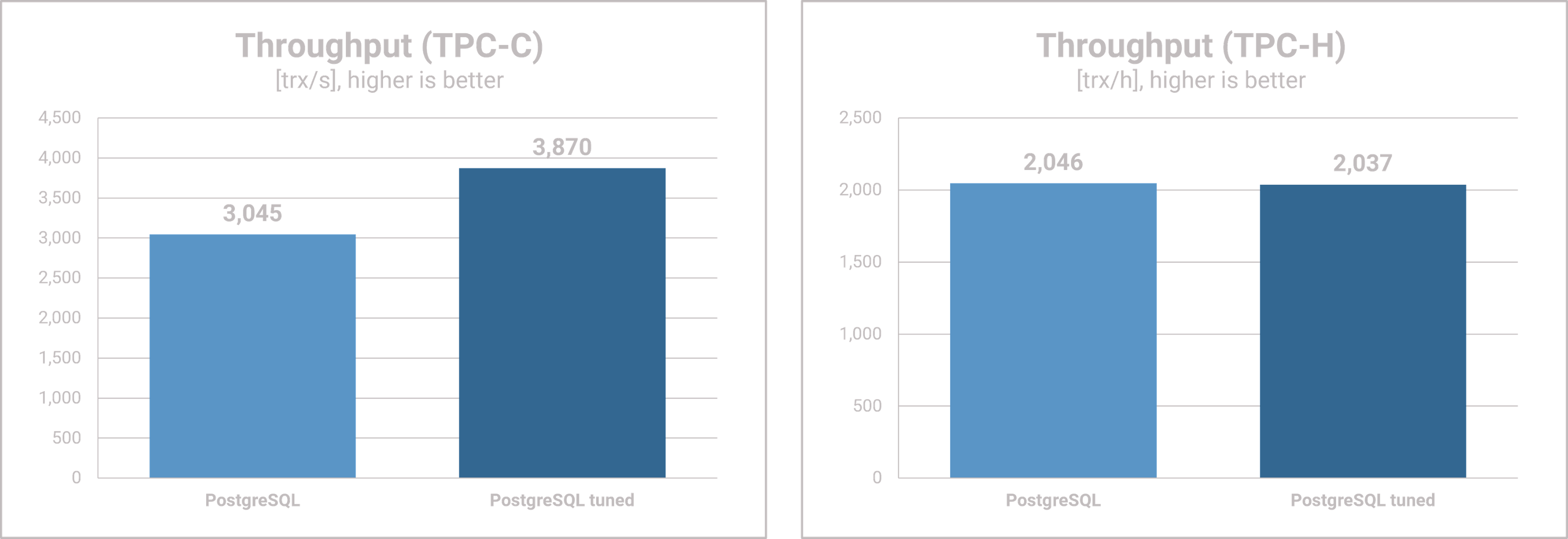
- For YCSB A, we see no changes in throughput between vanilla and tuned PostgreSQL.
- For the write-heavy YCSB B workload, however, we see an increase of almost 20%.
- For the OLTP workload of the TPC-C we see an improvement in throughput of even 30% due to the configuration tuning.
- For the TPC-H, which corresponds to a data warehouse / OLAP use case, we see no differences between the vanilla and the tuned configurations.
- It is interesting to note that the two rather write-oriented workloads, YCSB B and TPC-C, benefit from the tuning, while the read-oriented workloads, YCSB A and TPC-H, show no measurable gains.
Latency


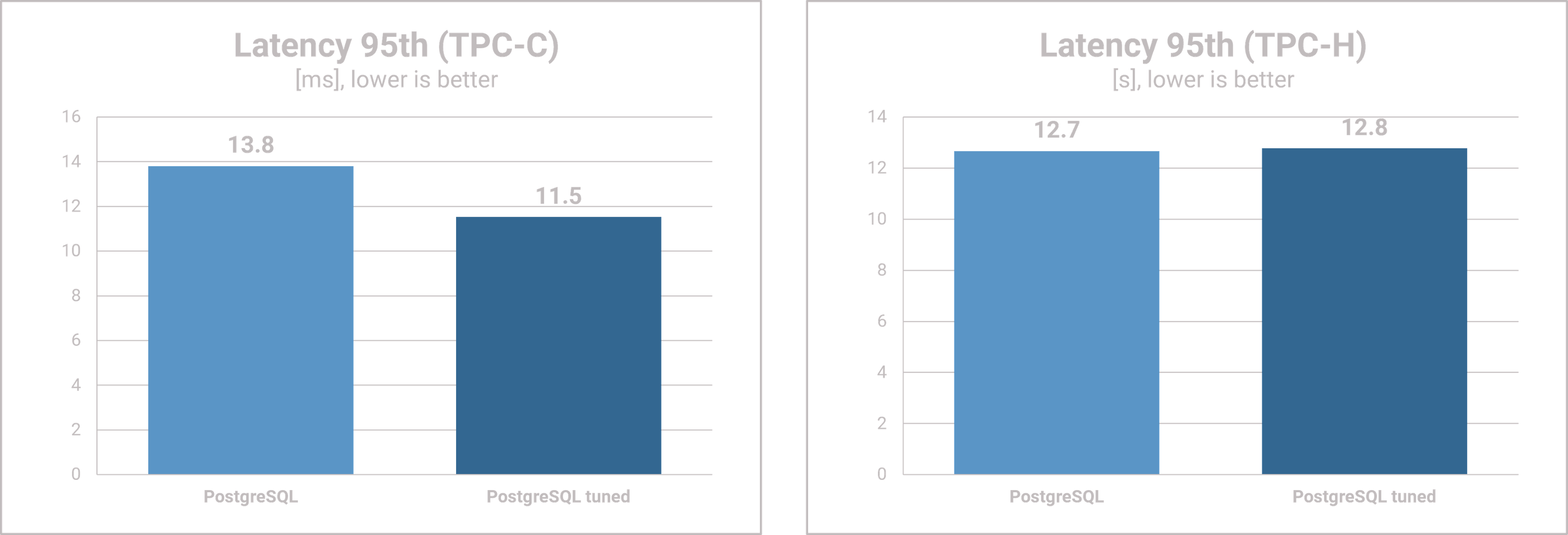
- The tuning has only a minimal effect on the read latency of the two YCSB workloads. However, the update latency of YCSB A increases significantly, while that of YCSB B decreases by approx. 10%.
- The TPC-C workload, on the other hand, benefits from tuning again and the combined read/write latency drops by almost 17%.
- For TPC-H, we again see no differences between vanilla and tuned PostgreSQL.
Summary
This small "Database Configuration Tuning 101" shows the basics and the difficulties of configuration tuning. Documentation, community and experts provide useful information and configurations. However, the effects on your workload and your system are not 100% predictable, as our benchmark measurements in this use case also showed.
It is interesting to see that the tunings for an analytical workload had a particularly positive impact on write-heavy workloads. Benchmarking can be used to achieve meaningful evaluations of the configurations and make sure, that no surprises happen.
Appendix – Benchmarking Specification
| DBMS Configuration | V15 |
|---|---|
| DBMS | PostgreSQL |
| Version | 15.4 |
| Cluster Type | single node |
| Cloud Configuration | DBMS Instance | Benchmark Instance |
|---|---|---|
| Cloud | OTC | OTC |
| Region | de-de | de-de |
| Instance Type | s3.2xlarge.4 | s3.4xlarge.2 |
| Instance Specs | 8 vCores/32 GB RAM | 16 vCores/32 GB RAM |
| Storage Type | Ultra-high I/O | Common I/O |
| Storage Size | 200 GB | 50GB GB |
| OS | Ubuntu 20.04 | Ubuntu 20.04 |
Appendix – Workload Specification
| YCSB Configuration | read-heavy | read-update |
|---|---|---|
| version | 0.17.0 | 0.17.0 |
| runtime | 30m | 30m |
| threads | 50 | 50 |
| initial data | 50 GB | 50GB |
| record size | 1 KB | 1 KB |
| read proportion | 95% | 50% |
| update | 5% | 50% |
| request distribution | zipfian | zipfian |
| BenchBase Configuration | TPC-C | TPC-H |
|---|---|---|
| Version | master | master |
| Runtime | 30m | 30m |
| Terminals | 20 | 2 |
| Scale Factor | 100 | 5 |