
How-to: Performance Benchmarking of MongoDB
"One accurate measurement is worth a thousand expert opinions." - Grace Hopper
This statement from one of the IT pioneers is still relevant today with the vastly growing amount of technologies to build data intensive and performance critical applications.
This article will explain what we learned and show you a how-to about performance benchmarks of one of the most popular NoSQL databases - MongoDB.
Let's dive in!
Table of Contents
- Chapter 1: Why Database Performance Benchmarking
- Chapter 2: Benchmark Suites & Supported Workloads
- Chapter 3: Benchmarking Databases in the Cloud: Best Practices
- Chapter 3: Summary & Lessons Learned
- About the Author
Why Database Performance Benchmarking?
In the context of database systems, database benchmarking is the common method to measure, analyze, compare and drive the development of database systems. While database benchmarking has been happening since the 1980s, the Seattle Report on Database Research published in 2022 highlights its importance for the current database landscape.
Modern database systems providers such as the market leading NoSQL database MongoDB have already adopted this statement for the cloud and database context as emphasized by the performance engineers of MongoDB: “...measure everything, assume nothing…”.
Based on this statement and since MongoDB as NoSQL market leader is a common target for benchmarks, this blog post addresses how to realize reproducible and transparent performance benchmarking of MongoDB in the cloud. For this, we rely on our benchmarking experience from both an academic background, where we evaluated distributed database systems in the cloud, and our industry experience in building the Benchmarking-as-a-Service platform benchANT. In particular, we discuss how operational database challenges can be supported with benchmarking, present a set of popular open source benchmark suites for MongoDB and provide an overview of the best benchmarking practices to achieve reliable and reproducible benchmark results.
Carrying out reliable, meaningful, transparent, and reproducible database benchmarks in the cloud is a complex task that requires domain knowledge of databases, clouds, and workload modeling. Therefore, benchmarking is often carried out by a dedicated benchmarking team. Often benchmarking is performed on dedicated database instances allocated for benchmarking purposes rather than using the production environment.
In this context, one must either rely on synthetic data that comes with the benchmark suite or use real-world data sets and query traces. Synthetic benchmark suites model common application workloads such as eCommerce or IoT applications and expose a set of configuration options for fine-grained workload modeling. While synthetic benchmarks usually are not able to map the real world workload 1:1, they enable benchmarking a broad range of what-if-scenarios such as varying workload intensities, data set sizes or query distributions.
Trace-based benchmarks come with significantly higher effort in the preparation phase: Traces need to be extracted out of the production system and compliance and security issues need to be handled. On the pro-side, they allow an exact emulation of the application specific workload, yet, with very limited configuration options.
Both benchmarking approaches provide detailed performance insights that can be exploited to enable data-driven decisions along the development and operation lifecycle for data intensive applications, as depicted in the following graphic.

Database Performance Comparison
When building a new data-intensive application, selecting the optimal database technology as storage backend is a crucial task. In this selection process, not only functional features such as query language and operational features are of importance. In addition, performance in terms of throughput and latency needs to be considered. Consequently, benchmarking the performance but also (horizontal) scalability of MongoDB in comparison to other potential database systems is an important task to enable data driven decisions.
In addition, since the DBaaS market is growing, there are many MongoDB-compatible DBaaS providers besides MongoDB Atlas. Applying benchmarks for comparing their performance and also throughput/$ is a valuable approach to enable data-driven decision-making.
Cloud Resource Performance Comparison
Similar to the database performance comparison, database benchmarking can also be applied to compare the resource utilization for operating MongoDB. Running application-specific benchmarks on different cloud providers with different VM instance types and storage types (e.g., AWS EBS types: GP2, GP3, io1, io2, etc.) enables the analysis of the optimal performance/cost ratio for a MongoDB cluster.
The following figures show a snapshot of the open database performance ranking for the performance of different cloud providers where a single node MongoDB Community Edition and a three node replica set has been benchmarked. More details on the benchmark results can be found in the details open database performance ranking or on GitHub.


Load & Stress Testing
Knowing the workload boundaries of your database setup before reaching these boundaries is crucial to ensure reliable database operations. Especially for greenfield applications, such boundaries are hard to estimate since historical data is missing.
In consequence, benchmarks can be applied to stress test the database cluster to analyze under which workload conditions the current setup will be overloaded, i.e. throughput decreases and latency constantly increases.
Database Scalability & Elasticity Benchmarking
MongoDB Atlas serverless provides automated scalability and elasticity out-of-the-box. In contrast, self-operated MongoDB installations may require scaling over time. Evaluating the scalability and elasticity (i.e. scaling MongoDB at runtime) via benchmarking is a common approach to understand the scaling impact before applying the actual scaling operations in production.
Any benchmarks can be applied for this approach, but additional orchestration tasks are required with respect to resource allocation, database deployment or workload increase. More conceptual details on database elasticity benchmarking can be found in our publication Kaa: Evaluating Elasticity of Cloud-hosted DBMS.
Optimization of Database Configuration
For existing applications that run with MongoDB, the mongo.cfg offers numerous knobs and tunables to optimize the performance for the application-specific workload. However, these knobs and bolts can be interdependent, and finding the optimal configuration currently is a hot topic in database research. One approach could be an explorative approach that builds upon large-scale benchmarks with different MongoDB configurations, but there are also ML-driven approaches for auto-tuning of database configurations, e.g. the Rafiki Framework and Ottertune.
However, none of these approaches support MongoDB, but MongoDB Atlas comes with the Performance Advisor which is a first step towards automated performance tuning. For self-operated MongoDB clusters, benchmarking the performance impact of different configuration options is a powerful approach to improve the performance of MongoDB in an exploratory manner.
Database Version Benchmarking
Every new MongoDB release comes with bug fixes and often includes new features that might have a positive or negative impact on performance. In consequence, it is a well established practice by database providers to run a series of different benchmarks internally to identify and resolve performance regressions before releasing the new version. MongoDB established a continuous performance regression testing framework to resolve this challenge. At the same time, this approach can be applied from the user perspective and a set of customer-specific or representative workloads before upgrading the database in the production system. This approach increases the operational confidence for a smooth upgrade of the production cluster.
With a similar approach, benchmarking can be applied to analyze new resource types released by the cloud providers with respect to their performance before applying them to operate MongoDB.
Total Cost Optimization
Since saving money is always an important aspect, benchmarks can be applied to analyze new cloud resource types that promise to be more cost-efficient by comparable performance, e.g. the latest AWS Graviton instance types. In consequence, benchmarks can be applied to verify these claims for MongoDB under different kinds of workloads before considering moving to new instance types.
The same approach can be applied for comparing different MongoDB and MongoDB compatible DBaaS offers, e.g. MongoDB Atlas and Azure CosmosDB for MongoDB. The following figures show the results of one of benchANTs customer projects with the goal to compare the throughput-cost ratio between MongoDB Atlas (M50 instance on Azure) and Azure CosmosDB for MongoDB for a write-heavy and read-heavy workload.


Benchmark Suites & Supported Workloads
For relational database systems, the development and standardization of benchmarks is mainly driven by the TPC - Transaction Processing Performance Council while benchmarks for NoSQL databases are mostly driven by the research and developer community and database vendors.
In the following, we present seven popular open source benchmark suites that are actively maintained. They either have a dedicated focus on MongoDB such as Genny or support MongoDB among other database systems.
The following table lists popular benchmark suites together with their supported workload types, since a benchmark suite can support different workload types. A workload is commonly defined as the data structure and the query types that are executed during the benchmark run. Depending on the workload, the queries can range from simple create-read-update-delete (CRUD) operations to more complex analytical queries that combine scalar and aggregate functions. Generally, these benchmark suites can be applied for all previously described use cases.
| Benchmark Suite | Workloads |
|---|---|
| Yahoo Cloud Serving Benchmark (YCSB) | CRUD |
| Time Series Benchmark Suite (TSBS) | Time-Series |
| NoSQLBench | CRUD, Time-Series & Tabular |
| Genny | CRUD, Time-Series, Batch Inserts & Micro Operations |
| mongo-perf | Micro Operations |
| py-tpcc | OLTP: eCommerce (based on TPC-C) |
| ClickBench | OLAP |
While most of these benchmark suites focus on the OLTP workload domain, the only benchmark that addresses the OLAP domain is ClickBench. A benchmark that addresses the emerging Hybrid Transactional Analytical Processing (HTAP) or real-time analytics workload domain is currently missing for NoSQL databases, while for relational databases a first benchmark suite is provided by the academic HTAPBench. The need to deal with time-series is a use case that has become dominant in many domains, including operations/observabilty and AI. The Time Series Benchmark Suite (TSBS) is an initial attempt in that exciting new field suited for benchmarking general purpose and specific time-series databases.
All of these benchmarks are designed to be extensible with respect to the supported database systems, but also with respect to the supported workloads. The extension effort heavily depends on the specific benchmark suite.
Benchmarking Databases in the Cloud: Best Practices
Executing reliable, comparable and transparent database benchmarks is already challenging, but benchmarking databases in the cloud increases the challenge due to volatile cloud resource performance and the options heterogeneous cloud offers as highlighted by the Seattle Report on Database Research.
The following figure depicts the common tasks that need to be carried out for benchmarking a database system in the cloud. In this context, the tasks select & configure benchmark and execute workload are well-supported by the listed benchmark suites, but the remaining tasks have to be carried out manually which is time-consuming and error-prone, or they can be implemented by relying on different cloud automation tools such as Ansible or Terraform.
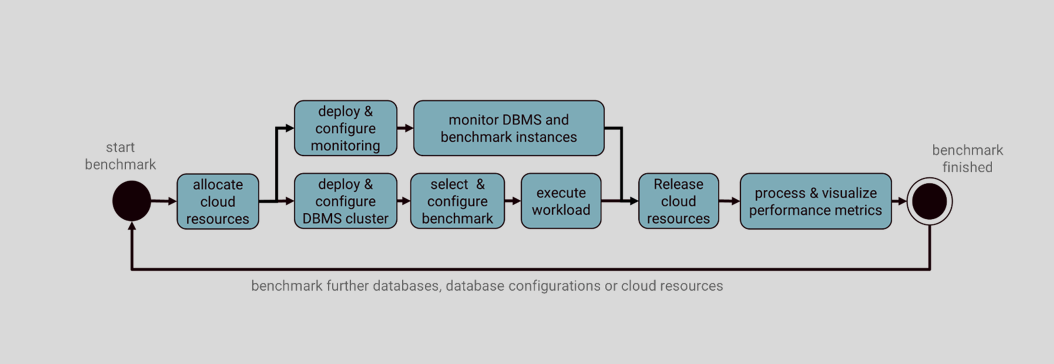
In addition, the research community provides various established guidelines on how to avoid common pitfalls in database benchmarking. Here, one practical example is the Fair Benchmarking Checklist.
With respect to performance impact factors in the cloud context (partially they also apply to a non-cloud context) four important but not all-encompassing dimensions exists, that need to be considered when running database benchmarks.

Lessons Learned
Database benchmarking provides you with the measurements that will support and enhance the implementation of data-intensive applications. However, carrying out reliable benchmarks requires a systematic approach. To summarize, our lessons learned that you might want to consider:
- Define your objective: before starting benchmarking, define if you are going to compare or optimize the existing MongoDB deployment for a specific workload or if you want to find the optimal cloud resources.
- Select your benchmark suite: the open source community provides multiple benchmark suites for MongoDB. They come with predefined workloads, but allow fine-grained workload configurations to model your application-specific workload.
- Automate for scale and reproducibility: running a few benchmarks can be done manually, but as soon as large-scale benchmark studies are required, it is highly recommended to automate the benchmark process to ensure reliable and reproducible results.
- Beware of impact factors: the database and cloud domains come with pitfalls that affect the reliability of the results. Recommended guidelines on how to avoid these pitfalls have been established, for example, the Fair Benchmarking Checklist, so make use of them.
About the Author
Daniel Seybold started his career as a PhD student at the Ulm University (Germany) in the area of cloud computing, with a focus on distributed databases operated in the cloud. Further interests cover cloud orchestration, model-driven engineering, and performance evaluations of distributed systems. After completing his PhD on “An automation-based approach for reproducible evaluations of distributed DBMS on elastic infrastructures”, Daniel has co-founded the Benchmarking-as-a-Service platform benchANT where he is responsible for the product development.